How to choose the best LLM fine-tuning technique for the project?


We’re witnessing an unprecedented AI rivalry nowadays. Companies across all sectors are deploying artificial intelligence solutions rapidly, recognising that AI implementation is no longer an option but a necessity for maintaining competitive advantage.
The truth is, AI is everywhere. You turn on your smart speaker, and the AI wishes you a pleasant day. You open a banking app, and AI helps you navigate financial decisions. AI creates your marketing materials, and recommendation systems suggest entertainment choices.
With new Large Language Models (LLMs) popping up every single week, constantly improving on the benchmarkings, you may wonder: Does it make sense to improve LLMs’ performance by yourself at all? And if so, how to effectively approach it and which strategy to choose?
In this article, I will guide you through the decision-making process for selecting the optimal LLM fine-tuning technique for your specific business needs. I will present three scenarios, each describing a particular use case.
What is LLM fine-tuning?
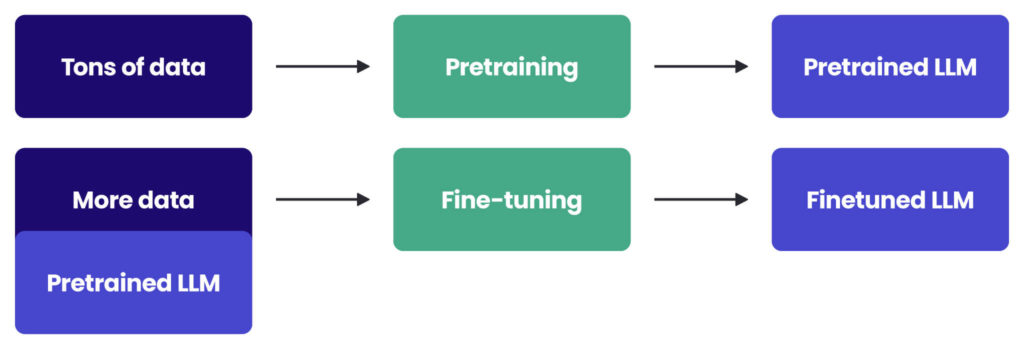
Fine-tuning of AI models is a technique that allows models to learn additional skills. It involves taking a pre-trained model and further training it on a task-specific dataset. AI models can be viewed as mathematical functions – there’s an input, processing, and an outcome. Training on large datasets allows it to gain intelligence.
With this in mind, an LLM is a neural network algorithm that knows only as much as the data used during its training. It learns from the content we use to feed it. Such transparency isn’t available when integrating third-party LLMs into your AI system. Even with open-source models, the training datasets typically remain unpublished, with very few exceptions such as StarCoder2.
After implementing fine-tuning, you gain additional influence over the model’s behaviour and skills that an LLM possesses. While LLMs available on the market can perform remarkable tasks, they often lack your organisation’s specific knowledge, the company’s best practices and data structures, specialised jargon, or domain-specific information. The fine-tuning of LLMs allows you to teach them these elements.
There is another important thing to note – the fine-tuning offers independence. If your AI system relies on LLMs via external APIs, you need to continuously monitor changes in these interfaces so that you can swiftly adjust the system in case a particular model is no longer supported by the provider. With your own fine-tuned models, there are no such dependencies, and the stability of your AI system is greater.
Where to start with the LLM fine-tuning?
You have an idea to kick off an AI project. Perfect! However, before you can celebrate success, you must thoroughly understand the project’s goals, requirements, and constraints. For simplicity, our goal here is to focus on the fine-tuning of LLM.
Goal
Start by formulating your objective in a single, comprehensible sentence.
Task
Define what skills your model should have: question-answering (QA), code completion, domain-specific knowledge (medical, finance, legal), multitasking capabilities, translation, etc.
Data
Formulate the data requirements for the task and ensure you have such data. If not, collect and prepare it. Publicly available datasets may also be helpful (e.g., on the Hugging Face platform). The fine-tuning requires high-quality (best verified by humans), diverse training data of sufficient volume.
Team
The LLM fine-tuning projects require multi-domain expertise, including data engineers, prompt engineers, data scientists, and MLOps specialists. Incorporating models into existing software demands programmers familiar with it. Domain experts play a crucial role in verifying model outputs.
Base Model
Before investing in fine-tuning, evaluate the currently existing models (previously mentioned Hugging Face or Ollama). This assessment requires a systematic approach (benchmarking), potentially with custom metrics relevant to your specific use case. It ensures that models are compared fairly using standardised criteria. It’s very important to check whether the model is open-source or under a commercial licence.
Timeline
The project steps involve selecting a base model, creating benchmarks, and collecting and preparing data. The LLM fine-tuning takes at least a couple of iterations of training and validation. Then deployment, integration and testing. You must consider all of this in the timeline.

Computing Resources
Working with LLMs requires substantial computing power, which is often costly. The fine-tuning demands even more resources than response generation (inference). Data security and privacy are key factors to consider when choosing infrastructure. Even skilled AI engineers need multiple experiments to optimise model parameters such as learning rate, batch size, and dropout. This is highly use-case specific. Moreover, the results depend on combinations of parameters rather than on individual values.
Serving
Decisions on whether to deploy the fine-tuned model with cloud services or on-premise solutions significantly impact the project. They affect model performance, scalability, costs, and implementation timeline. For highly sensitive data, you may need local processing or safer protocols. Response latency is often as critical as output quality. Acceptable waiting times, whether 10 seconds or several minutes, must meet user expectations and business requirements. Larger models generally deliver better results, but with increased latency and computing power consumption. Longer prompts with more context require additional processing time. Stronger hardware reduces response times but increases expenses.
Now that you know how to define the project premises, let’s dive deep into some practical scenarios of AI projects with the LLM fine-tuning in the scope.
Scenario 1 – full LLM fine-tuning
The healthcare technology company provides software solutions to optimise clinical data workflows for multiple hospitals and medical facilities. The technical team includes experienced ML engineers with expertise in healthcare AI applications. The company established partnerships with clinical experts and possessed a comprehensive dataset containing over 50,000 anonymised patient records, each paired with clinical summaries created by experienced clinicians. The company’s cloud infrastructure includes NVIDIA H100 GPUs, providing substantial computational power for machine learning applications. Security of sensitive healthcare data is ensured and maintained in accordance with relevant regulations.
![LLM fine-tuning technique for Connected healthcare [Subtitle] Intelligent clinical data ecosystem [ Middle] AI platform [Other] Hospital Clinic Lab facility Medical centre](https://spyro-soft.com/wp-content/uploads/2025/06/image-22-1-1024x746.jpg)
Goal:
“As a medical professional, I want to have access to an AI system that generates standardised clinical summaries from patient records, lab results and clinical notes.”
The LLM must be able to synthesise complex medical information from multiple sources and generate comprehensive clinical summaries that meet strict medical documentation standards. As a result, the time spent on administrative documentation will be reduced, allowing for a greater focus on direct patient care. The standardised summaries will improve communication between healthcare providers and ensure consistent quality of documentation.
The project must be accomplished within six months.
After assessing available models, the team determined that existing pre-trained models fail to meet the specific requirements and lack the specialised medical knowledge required for this application. The team proposes to conduct full fine-tuning of the Llama 3.3 70B model due to its open-source nature, high parameter number with substantial knowledge capacity, and promising instruction-following capabilities.
The team’s proposal makes sense, as the desired solution requires specialised medical knowledge beyond what’s available in general models. The decision to go with full fine-tuning is also supported by available resources. The project’s timeline is reasonable, considering the task’s complexity. The team has required expertise and support from domain experts. There is also a large amount of high-quality data available. The cloud infrastructure with NVIDIA H100 GPUs will support the computational demands of full fine-tuning a 70B parameter model. Once deployed, the fine-tuned model will operate on secured cloud infrastructure, generating summaries nightly for patients scheduled for appointments the following day, with additional on-demand processing available within minutes when needed. The results will be stored in a secure database for easy retrieval by authorised healthcare providers.
As demonstrated in this case, if you’re building an AI system for highly specific areas like healthcare – where accuracy, compliance, and specialised knowledge are critical – you should prioritise access to domain experts and conduct the full fine-tuning of high-capacity models. Doing so helps ensure that your infrastructure can handle specific data and deliver quality outputs in line with the standards of a particular sector.
Scenario 2 – Parameter-Efficient Fine-Tuning (PEFT)
This scenario describes my very recent project. We executed it in partnership with Qt. The Qt company created Qt Creator IDE, a cross-platform, integrated development environment (IDE) for application developers to create applications for multiple desktops, embedded, and mobile devices. Qt Creator’s advanced code editor supports C++, QML, JavaScript, Python, Rust, .NET, Swift, Java/Kotlin and other languages. It features code completion, syntax highlighting, refactoring and has built-in documentation at your fingertips.
The Qt company wanted to integrate AI into the Qt Creator IDE to enhance developer productivity even further. And it happened; you can check on Qt AI Assistant. One of the Qt AI Assistant skills is code completion in QML language, which will be the focus of this scenario. QML is a declarative language that allows for describing user interfaces in terms of their visual components and how they interact and relate with one another. Qt 6 is the latest version of Qt.
Source: Qt AI Assistant
Goal:
“As a developer, I need to have access to an LLM-expert in QML Qt6 coding that can provide intelligent code completion within Qt Creator IDE.”
The Qt company has skilled engineers on board. Team composition with Spyrosoft as a partner was a piece of cake. The team consists of Qt Creator developers, and experienced AI and software engineers.
Qt has created a specialised dataset consisting of over 5,700 high-quality QML Qt6 code samples written by dedicated developers. These samples were processed into training triplets (prefix – code before the cursor, middle – to be suggested by LLM, and suffix – code after the cursor) for the Fill-in-the-Middle (FIM) task, resulting in an enormous number of training examples reflecting the way code is being developed accurately.
The team created a custom benchmarking tool to evaluate available models. Such a benchmarking approach helped determine that existing pre-trained models achieve mostly about 50- 60% accuracy, with some going even over 80%, but all are missing many of the latest features and best practices specific to QML Qt6. However, there are specialised code2code models performing very well in common programming languages such as Python or C++.
The Parameter-Efficient Fine-Tuning (PEFT) technique was used to create the LLM-expert in QML Qt6 coding. PEFT fine-tuning is like personalising a pre-trained AI model by adjusting only a small part of it rather than the whole model. This approach saves both time and computing resources while also providing excellent results for specific tasks. The chosen base models are Code Llama 7B and 13B due to their strong code generation capabilities, being open-source and smaller size, enabling local deployment (though Code Llama 13B performs much better through the cloud). For fine-tuning training, a multi-GPU cluster with NVIDIA A100 cards was enough; for inference, a single A100 card provides close to real-time code suggestions.
The custom models are integrated seamlessly with the Qt Creator IDE, along with preprocessing of requests and post-processing of the responses for even better QML Qt6 code quality. The models are also available on Hugging Face and Ollama platforms in an open-source manner, making them even more accessible to the broader Qt developer community.
This example shows that if you care about the swift creation of custom models that deliver expert-level completions for subjects or coding languages not handled by available LLMs, you can benefit by using Parameter-Efficient Fine-Tuning (PEFT). With already prepared high-quality data or samples and the option to personalise only a chunk of an open-source model fast, you can easily optimise required resources, performance, and outcomes for specific tasks and your unique needs.
Scenario 3 – alternatives for fine-tuning methods
The mid-size insurance company processes thousands of claims daily. The company has established a clear workflow for maintaining documentation quality and regular updates to policy guidelines. The technical team consists of data scientists and DevOps professionals. The company possesses a large corpus of insurance documents, internal policies and guidelines, as well as relevant regulations. There are frequent updates and changes to the documents. The document database is already implemented and maintained. The stored data contains proprietary and sensitive information. The company’s infrastructure includes API access in a secure cloud environment, but it lacks GPU machines for large-scale AI deployments.
Doubled efficiency with AI automation for insurance company
Go to case study
Goal:
“As a claim agent, I want to have an AI Assistant that can answer my questions about policy and claims details.”
The AI system must be able to access, retrieve, and synthesise information from multiple documents to provide accurate answers about claim details, policies, and regulations. It is also crucial for the system to provide references and citations to ensure transparency and explainability. As a result, claim processing time can be reduced, allowing for more efficient customer service and improved productivity.
The time for the project is three months.
Having analysed the project requirements and constraints, the team determined that fine-tuning is not possible due to limited resources and timeline. Moreover, frequent data changes wouldn’t be available without retraining. The team proposes building a Retrieval Augmented Generation (RAG) system using GPT-4o or Claude 3.5 Sonnet in a secure cloud environment. Both models have large context windows to digest multiple documents and strong domain understanding. The database with all the documents is already in place.
The proposed solution enables the quick incorporation of updated information and provides explainability through references and citations. The large corpus of documentation creates a solid foundation for the knowledge database. The cloud API infrastructure supports secure deployment in a closed environment. The RAG system can connect to the company’s document database and retrieve relevant information based on claim processors’ queries.
In this example, you can see that when operating in a domain with frequent changes and updates of documents and data, it is worth considering alternative approaches instead of fine-tuning, such as RAG (Retrieval Augmented Generation). They can handle information updates and seamlessly integrate them into responses without compromising quality, speed, or security.

Wrap up on LLM fine-tuning methods
There’s no universal approach to implementing LLM solutions. The appropriate technique depends on your unique combination of goal, resources, and constraints.
Your choice fundamentally depends on the given use case: company readiness, including the team and their expertise, data availability, and computing resources. Timeline constraints directly impact the decision on approach – successful fine-tuning requires significant time, whereas alternatives such as RAG can be delivered faster. The quality of responses from currently available models determines the need for additional training. Frequent changes in data make continuous retraining impractical. Serving options offer flexibility in system design – integrating third-party APIs ensures low latency, local deployment provides excellent control and security, and cloud environments deliver scalable performance for your custom models.
If available solutions don’t meet your expectations, don’t worry. You can create your own. While LLMs are impressive, large general-purpose models aren’t always necessary. Smaller LLMs can be remarkably powerful with customisation and additional training for specific needs. Properly fine-tuned models can outperform larger general models for specialised tasks.
AI implementation is a journey of continual learning and adaptation. As technology evolves and your organisation changes, the approach may need to evolve as well. The most successful AI strategies remain flexible, focusing on delivering tangible business value.
Looking for a well-suited LLM fine-tuning approach to extend your AI solutions and meet your business challenges? Let’s talk about how we can help you find the best strategy for your project.




Fine-tuning is the process of training a pre-built language model on your own domain-specific data so it produces outputs tailored to your context. You need it when a general-purpose model lacks the specific knowledge, terminology, or behaviour your use case requires, and when prompting alone is insufficient to achieve consistent results.
Full fine-tuning updates all model parameters on your dataset, which requires significant compute but produces the most specialised results. Parameter-Efficient Fine-Tuning (PEFT) updates only a subset of parameters, conserving resources while still achieving strong domain performance. Retrieval Augmented Generation (RAG) retrieves relevant documents at inference time rather than baking knowledge into the model, making it better suited to frequently changing information.
Before selecting a technique, you need clear goals, defined tasks, high-quality training data of sufficient volume, appropriate compute infrastructure, and a realistic timeline. The choice of technique depends on the interaction of all these factors. Teams with limited GPU access and dynamic data are often better served by RAG than by fine-tuning.
Full fine-tuning of large models such as Llama 3.3 70B requires significant GPU resources such as NVIDIA H100 hardware. PEFT approaches using smaller models like Code Llama 7B or 13B are considerably less resource-intensive, making them viable for organisations without dedicated high-performance compute infrastructure.
Fine-tuning is not well-suited to frequently changing data because the model would need continuous retraining. RAG handles this scenario more practically, retrieving up-to-date documents at inference time without requiring a new training run. An insurance company with regularly updated policy documentation is a good example of where RAG outperforms fine-tuning.
arrow_circle_rightContact us
Get in touch and let’s discuss how we can help you

Tomasz Smolarczyk
Director of Artificial Intelligence
arrow_circle_right Our articles



