Mitigating AI risks with best practices for LLM testing


Imagine launching a groundbreaking AI tool, only to have it propose biased decisions, fabricate legal citations, or misdiagnose a health condition. These aren’t hypothetical scenarios – they’re real-world failures that erode trust and create serious risks. Notable examples include models like Gemini and ChatGPT providing inaccurate information about science and history, Air Canada’s customer service AI chatbot offering non-existent promotions and refunds to the clients, and AI-powered health assistants generating misleading medical advice or recommending unsafe treatments. Hallucinations can have various causes, but usually, we can detect them through LLM testing and take corrective action when needed.
Adopting the latest AI models, switching to another one, or expanding system capabilities is appealing. The pace of updates and the variety of adaptations has accelerated, with multiple major model releases and an increasing number of new use cases in short timeframes. These imply changes in our productivity, enhance our capabilities, and help us focus on what matters, but also introduce risk for the end-user.
Balancing innovation with reliability requires testing protocols. As AI technology advances, so do the strategies and frameworks for ensuring dependable performance. In this blog post, we’ll first explore the key risks of unreliable AI and then discuss LLM testing protocols to mitigate these challenges.
Key risks to address in LLM testing
AI models bring powerful capabilities but also challenges. The following are some of the most pressing risks organisations must consider when deploying and maintaining large language models (LLMs).
Inconsistent or misaligned outputs
One of the biggest challenges in testing large language models is ensuring consistency and alignment with expected behaviour. LLMs can produce responses that vary significantly for similar inputs, leading to reliability issues in applications requiring precise or repeatable answers. Additionally, models may generate outputs that deviate from brand guidelines, ethical considerations, or regulatory requirements.
Performance drop in key tasks
When upgrading your model to a newer version, you need to take particular care, as it doesn’t always lead to universal improvement. A 2024 study found that model updates can degrade performance in specific tasks, impacting critical applications like content moderation and customer feedback analysis.
Insight: A 2024 study on Regression Testing for Evolving LLM APIs showed that 58.8% of prompts used to instruct the model to classify given text as toxic or non-toxic exhibited decreased accuracy after the model was updated to a newer, more advanced version.
Source: (Why) Is My Prompt Getting Worse? Rethinking Regression Testing for Evolving LLM APIs

Data drift
AI models depend on the data used to train them. Over time, changes in language, emerging trends, or shifts in customer behaviour can render models less accurate. This phenomenon, known as “data drift,” can lead to outdated or irrelevant predictions.
AI-specific security threats
AI systems face unique security risks, including prompt injections (tricking AI into generating unintended or harmful outputs), data poisoning (feeding malicious data to corrupt results), and data leakage (unintentionally exposing sensitive information). Tools like Lakera Guard help secure large language models in real time.
Insight: Curious about prompt attacks? Try Gandalf by Lakera – a game where you test your skills to trick the model into revealing secret information.
Latency and slow responses
Large AI models can be computationally intensive, leading to slower response times. For real-time applications – such as financial trading algorithms or live customer support – these delays can have significant repercussions, including missed opportunities, disrupted workflows, and frustrated users. In high-stakes environments, even slight lags can lead to financial losses, security risks, or decreased trust in AI-driven decisions.
Escalating costs
Sophisticated AI models typically require increased computational resources. Cloud processing fees, storage demands, and energy consumption can accumulate, complicating scalability. Achieving a balance between performance and cost is needed for sustainable AI integration.
Regulatory compliance risks
With regulations like the EU AI Act and GDPR taking effect, AI compliance is critical. Organisations must ensure their artificial intelligence systems do not violate legal standards, such as data privacy laws or restrictions on high-risk AI applications.

AI and LLM testing protocols
Understanding AI risks is just the first step in building proactive testing strategies. To ensure LLMs and AI models deliver consistent, high-quality outputs, we need structured validation methods.
Measure model response quality
A straightforward approach to validating AI reliability is to build a dataset containing a collection of prompts paired with expected response guidelines. Such a solution acts as a benchmark to test whether the model behaves as intended across key scenarios.
During testing, the model’s outputs are compared to expected responses for assessment of such matters as:
- Consistency – Does the AI produce stable responses for the same input?
- Correctness – Are outputs factually accurate and aligned with guidelines?
- Robustness – Can the model handle variations in phrasing without contradictions?
- Format – Does the response follow the required structure (e.g., JSON, tables)?
- Compliance – Does the AI meet ethical, legal, and policy standards?
If discrepancies arise, we can address them through fine-tuning, prompt adjustments, or fallback mechanisms.
Case study: Data extraction with large language models
For several of our clients from the ecommerce and logistics sectors, we created an automated data extraction solution. The enhanced process of separating and verifying business data from PDF files and operational documents has helped them eliminate slow, manual data entry and email forwarding. Using the GPT4o model, structured data was extracted and validated through automated routines, generating accurate JSON outputs ready for further processing in seconds, rather than minutes, per document.
- LlamaIndex workflows facilitated iterative improvements, refining extraction quality in complex cases where initial execution failed validation.
- MLflow, widely used for managing the machine learning lifecycle, was integrated to track experiments and monitor performance.
As a result of these projects, our solutions drastically reduced processing time, improved accuracy, and minimised manual intervention, enabling faster decision-making and streamlined operations.
Check how AI data extraction is helping our insurance client
See case study
Model acting as a judge
When tasks require subjective judgment – such as evaluating conversational AI, summarising complex texts, or translating nuanced content – the LLM-as-a-judge framework can be highly effective. This approach leverages the AI’s capabilities to critique and score its outputs.
Carefully designed evaluation prompts enable performance assessment. Specially designed instructions allow us to assess how well a model performs under certain conditions. This method is particularly valuable when we need a human-like judgment, but full automation remains the goal.
Case study: Translation validation for the chemical industry
As part of our project for a leading company in the chemical industry, we validated AI-generated translations of its website content, which included product information and marketing materials. Our goal was to ensure factual accuracy and compliance, as errors in toxicity warnings, numerical values, and health-related terms could mislead customers and harm brand credibility.
A competing LLM, developed by another AI provider, validated the original outputs for toxicity detection, health and safety risks, and factual accuracy – focusing on named entities, numbers, dates, and units. Tools like Promptfoo enable model and prompt comparisons, identifying the most effective configurations for ensuring consistency and accuracy in sensitive areas.
Results for Polish as the pilot language with translations across more than 200 websites show an 87% decrease in error rates after automated translation improvements. The project also brought a 75% reduction in translations requiring human review, significantly improving content reliability, reducing costs, and minimising manual effort.

Start with manual reviews, advance to automated testing
In some cases, initial manual evaluations are necessary to set up quality benchmarks. By analysing patterns in high- and low-quality outputs, we can get insights that help design automated testing workflows.
The collected inputs can be reused to prevent performance regression. Reprocessing historical data with updated models, in a process known as backtesting, ensures consistency and reliability over time.
Case study: Ensuring translation consistency with LLM testing and validation
During our project assessing AI-generated translations, it became clear that inconsistencies in proprietary terms, marketing slogans, and industry-specific phrases were a significant challenge. Wanting to translate content into 28 languages from various language groups, such as Germanic, Romanic, Slavic, Asian, Middle Eastern, and Finno-Ugric, the client needed a new approach to address the issue.
Experts created a glossary of approved translations, ensuring that key terms remained uniform across all languages, with some left in English to preserve brand identity. The glossary was then integrated into the validation process, helping automated translations maintain accuracy and consistency across international markets.
Customising your LLM testing suite
Industry experts use the approaches outlined above widely. However, it is important to remember that AI systems vary in complexity, capabilities, and limitations. That’s why, to ensure effective LLM testing, you may need strategies tailored to specific functions and behaviours.
For example, retrieval-augmented generation (RAG) models require validation of how well they integrate external data, while models with different memory mechanisms demand specialised consistency checks. Similarly, agent-based AI workflows, designed to operate autonomously, need testing frameworks that assess decision-making and adaptability.
By aligning testing strategies with each model’s unique characteristics, organisations can ensure more reliable, context-aware, and high-performing AI systems.
AI performance and cost monitoring
Assuring long-term AI reliability requires ongoing tracking of performance and resource usage. Continuous monitoring helps detect anomalies, optimise efficiency, and prevent regressions in production environments.
Optimising computational resources, managing token consumption, and refining model usage help balance performance with efficiency. Regular audits and adjustments ensure sustainable AI operations without unnecessary costs.
Automated monitoring tools, such as OpenAI’s API Dashboard, AWS CloudWatch, and Azure Monitor, track key performance metrics and identify deviations. This proactive approach helps maintain model consistency and responsiveness.
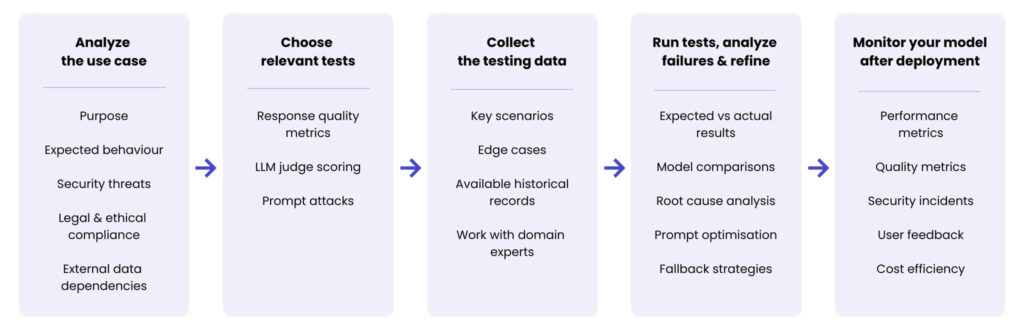
LLM testing pipeline
The LLM Testing Pipeline diagram presented below puts all the key concepts discussed in this article in order. By following this structured approach – from analysing the use case to monitoring performance – teams can systematically assess model quality, refine outputs, and maintain long-term reliability.
Leverage LLM testing protocols with a proven tech partner
Without structured evaluation, model updates can introduce inconsistencies, degrade accuracy, or increase operational costs, undermining trust and efficiency.
Fortunately, AI testing has evolved alongside the technology itself. From structured validation techniques to automated monitoring, businesses can now access methodologies that mitigate risks without stifling innovation.
As the adoption of large language models accelerates, the demand for specialised AI and LLM testing expertise will only grow. Organisations that invest in strong validation frameworks today will have the best chance to harness AI’s full potential – while maintaining control over performance, security, and costs.
So, if you want to keep your organisation at the forefront of innovation by leveraging and expanding proven and meticulously tested AI solutions, contact us via the form below.
FAQ
Common concerns are hallucinations, inconsistent responses, and misleading outputs that lead to reliability issues. Performance drops can also pose risks, as upgrading a model doesn’t always guarantee better results. Data drift is also challenging, with AI data becoming outdated as languages, trends, and user behaviour evolve. AI-specific security threats, such as prompt injections, data poisoning, and leakage, can compromise models, while latency issues may slow real-time processing. Additionally, maintaining AI infrastructure can be costly due to high computational demands, and involves aligning with regulatory standards.
LLM testing helps identify weaknesses and ensures consistent performance by evaluating response accuracy and stability, detecting model regressions after updates, and monitoring for security vulnerabilities. It can also play a significant role in ensuring regulatory and ethical compliance.
Implementing LLM testing effectively requires a structured approach. The process should include manual reviews to set quality benchmarks and automated testing to improve performance and efficiency. Measuring model response quality involves comparing outputs against expected answers to assess accuracy. Using LLM as a judge helps leverage the AI’s capabilities to critique and evaluate its outputs, while backtesting helps ensure model consistency over time, even after new model updates.
To balance AI performance with cost efficiency, businesses should optimise computational resources, and manage token and model usage to prevent waste. Cost-effective cloud solutions can help manage expenses, while implementing performance monitoring tools like OpenAI’s API Dashboard, AWS CloudWatch, and Azure Monitor ensures efficient use of resources without sacrificing reliability.
Without structured evaluation, AI systems can introduce inconsistencies, degrade accuracy, and increase costs. Robust LLM testing frameworks ensure that models remain reliable, compliant, and efficient, helping businesses unlock AI’s full potential while mitigating risks associated with unpredictable performance.




arrow_circle_rightContact us
Let’s discuss how we can support your AI projects

Tomasz Smolarczyk
Director of Artificial Intelligence
arrow_circle_right Other articles





