Edge AI in agriculture: designing systems that work without connectivity


Rural connectivity has improved, but it is still too inconsistent to support cloud-dependent agricultural software as the default operating model. In practice, field operations, machinery workflows, sensor systems, and time-critical alerts must continue to work during network loss, weak signal, or high-latency conditions.
That is why edge AI in agriculture is not a feature upgrade. It is a systems design requirement that makes a tangible contribution in transforming agriculture and sustainable farming practices. Teams building precision agriculture platforms, connected machinery, and agronomic decision tools need offline-first architectures, local inference, resilient synchronisation, and deterministic fallbacks if they want their software to perform under real-world farm conditions.
Why offline-first matters in sustainable agriculture?
Agriculture is not a regular software environment. Fields are large, weather conditions are changeable, assets are mobile, infrastructure is uneven, and many workflows happen outside stable network coverage. Even in places where 5G rollout has progressed, rural quality still lags urban quality. Across the OECD countries, at the end of 2024, users in cities experienced mobile download speeds 37.2% higher than users in rural areas, and the average 5G download speed was 222.6 Mbps in cities versus 173.5 Mbps in rural areas.
The gap is not only about average speed. It is also about consistency, latency, signal dropouts, roaming behaviour, and the operational reality in which many farming operations and tasks happen at the edge of coverage, inside steel machinery cabins, in orchards, in remote plots, or across mixed topography. The European Commission’s 2024 broadband coverage assessment explicitly tracks rural availability separately because coverage quality and rollout remain uneven by geography.
FAO has also highlighted a broader structural issue: digital exclusion in rural areas grows as services are digitalised and offline alternatives are removed. That principle applies directly to agricultural software and digital technologies. If a spray log, disease alert, irrigation rule, or machine instruction only works online, then the system has been designed against smart farming rather than with it in mind.
What problems does edge computing solve for precision agriculture?
Edge computing addresses one of the most persistent constraints in agricultural digital technologies and systems: the gap between how software is designed in connected environments and how it must actually perform in the field, where latency, limited bandwidth, and unstable connectivity are part of everyday operations.
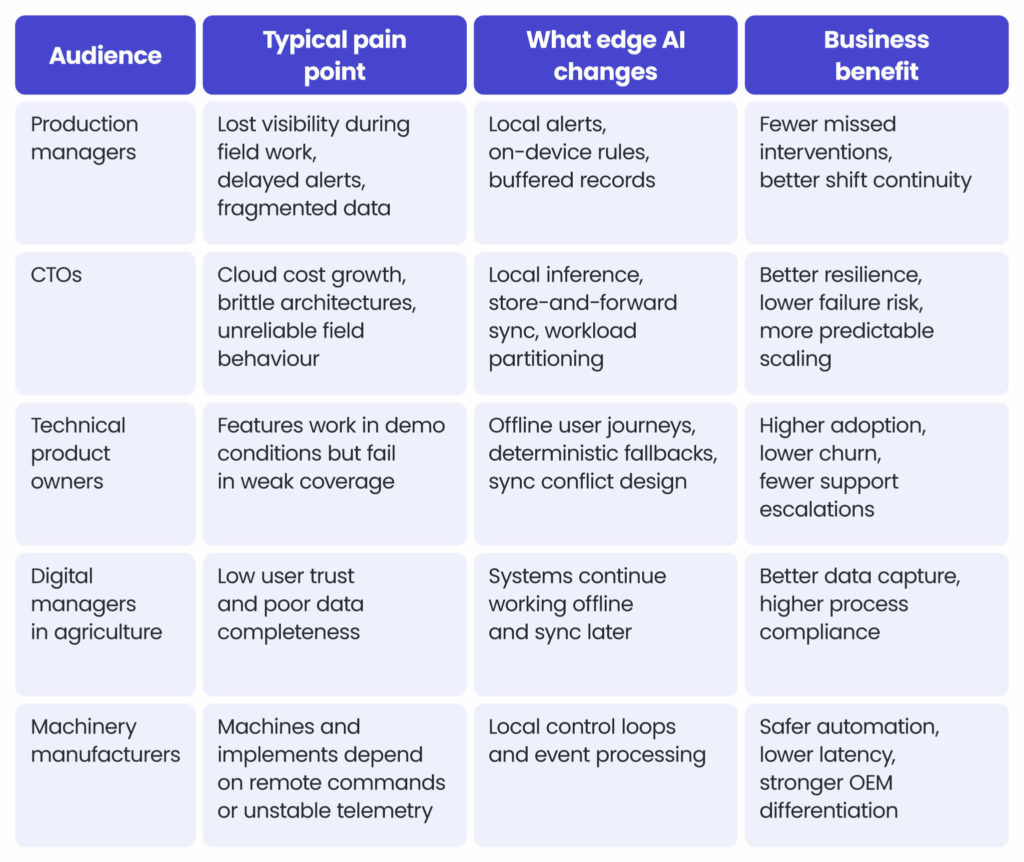
Why does this matter commercially regarding transforming agriculture?
For software buyers in the agricultural sector, reliability is often valued above algorithmic sophistication. A model with slightly lower laboratory accuracy but strong local execution, good fallback logic, and robust synchronisation can create more operational value than a more complex cloud-dependent system. That trade-off is consistent with current edge computing research in agriculture, which emphasises latency reduction, bandwidth efficiency, and distributed decision-making close to machinery, sensors, and crops.

Cloud-first vs edge-first in agricultural systems
Cloud platforms in smart farming still matter. It is the right place for fleet-wide reporting, model retraining, cross-farm benchmarking, traceability, planning, and long-term analytics. The mistake is assuming it should sit on the critical path of every field decision.
Comparison of architecture choices
The comparison below provides a simple way to understand how cloud-first and edge-first architectures differ in day-to-day operations, particularly in environments where connectivity, response time, and system continuity have a direct impact on performance in the field.
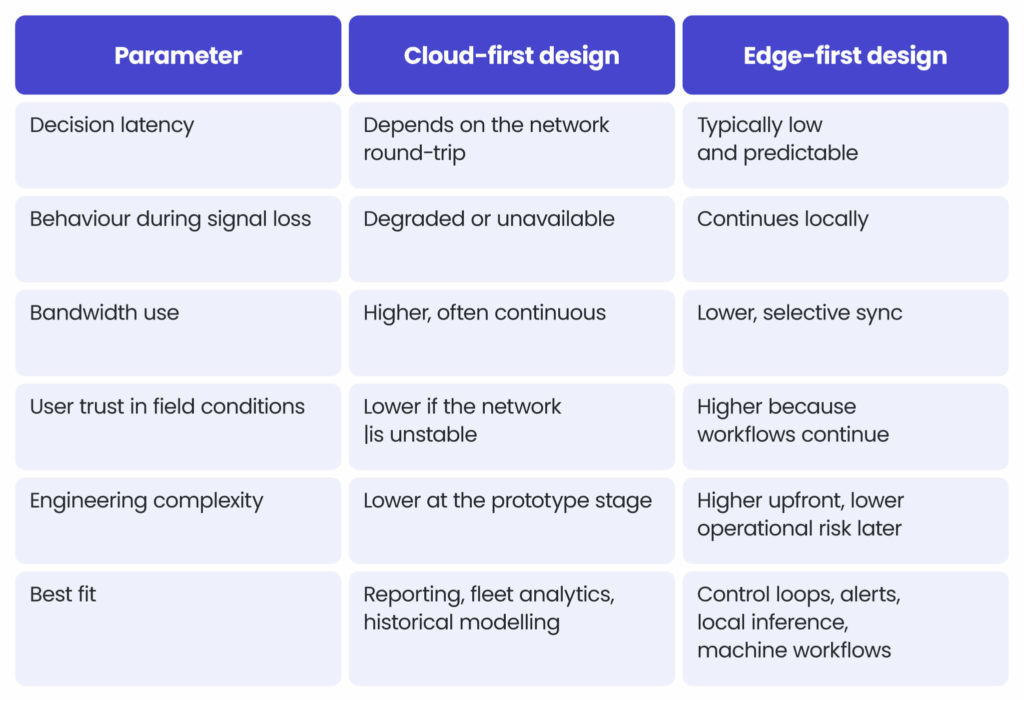
Where cloud should remain central in smart farming
Cloud infrastructure remains essential in agricultural systems, but its main role is not to play a critical part in every operational decision. Its real value lies in scale, coordination, governance, and the ability to combine data across machines, users, farms, and seasons. Wherever the task depends on a broad system view, shared standards, long-term storage, or central control, the cloud should remain the primary layer.
Cloud is still the right home for:
- model training and version governance,
- fleet-wide data normalisation,
- regulatory reporting,
- ERP, CRM, and supply-chain integration,
- historical trend analysis and data processing across seasons and farms.
Where edge AI and computing should be the default
Edge computing should be the default for functions that must work in real time, close to the machine, sensor, or operator, and without assuming stable connectivity. In modern agriculture and farming operations and environments, many of the most important workflows happen in the field, under weak signal, variable latency, or complete network loss. Wherever the task depends on immediacy, local context, operational continuity, and resilience, the edge should own the execution.
Edge should own:
- sensor ingestion and filtering,
- event detection,
- local recommendations and alarms,
- machine-side decision support,
- emergency fallback logic,
- offline operator workflows,
- buffering and store-and-forward transmission.
The engineering principles behind robust edge AI in agriculture
Move decision logic close to the event
If a frost alarm depends on a round trip to the cloud, it is already too late in many scenarios. Local thresholding, local feature extraction, and local inference reduce risk. Recent research in agricultural edge systems repeatedly frames this as a practical response to bandwidth constraints, lower response efficiency, and resource-sensitive deployment environments.
Build for synchronisation, not permanent connectivity
The right mental model is not “a connected device”. It is “an autonomous local node that synchronises when possible”. This changes how teams design message queues, timestamps, retry logic, idempotency, conflict resolution, and audit trails.
Separate hard real-time from soft real-time
A machine safety or actuation rule cannot wait for the same pipeline that updates a dashboard. Teams need explicit classes of decisions:
- immediate local decisions,
- local decisions with later cloud confirmation,
- cloud decisions pushed asynchronously,
- historical analytics only.
Optimise models for deployment, not only for benchmark accuracy
Agricultural edge AI often succeeds with smaller models, compressed models, quantised inference, or hybrid rule-plus-model pipelines. A recent 2025 smart agriculture framework showed that lightweight edge-optimised models can achieve 88% weather classification accuracy and 93% crop classification accuracy on resource-constrained hardware, while still supporting real-time local actuation logic.
Treat local storage as a first-class system component
Offline-first systems need durable local storage, not temporary cache used as an afterthought. This includes:
- local event logs,
- operator actions,
- telemetry buffers,
- model versions,
- configuration snapshots,
- sync state and audit metadata.
How to design an offline-first agricultural workflow
Below is a practical implementation sequence for product and engineering teams wanting to build reliable precision agriculture systems.
Step 1. Identify decisions that must survive network loss
List all workflows and mark which ones fail if the cloud is unavailable. In most agricultural systems, these include alerts, machine-side recommendations, offline field records, sensor-triggered actions, and operator task confirmation.
Step 2. Define what runs locally
For each critical workflow, specify:
- local inputs,
- local processing,
- local output,
- fallback output if the model is unavailable,
- what must be synchronised later.
Step 3. Reduce payload size and sync frequency
Do not send raw streams when summarised events will do. Send features, flags, compressed histories, and priority deltas where possible. This reduces bandwidth pressure and preserves battery life.
Step 4. Design conflict handling before deployment
Offline data capture creates merge events. Two operators may edit the same task. A machine may complete work before the cloud plan updates. The product needs clear rules for precedence, reconciliation, and auditability.
Step 5. Create an operator-visible sync state
Users must know whether an action is:
- saved locally,
- pending synchronisation,
- synchronised,
- rejected,
- overwritten by a newer version.
This is not only a technical detail. It directly affects trust.
Step 6. Benchmark in realistic rural conditions
Test under:
- weak 4G,
- intermittent coverage,
- long offline windows,
- battery constraints,
- gateway reboot,
- delayed clock sync,
- partial data corruption.
Use case: Orchard frost and disease monitoring with local decision logic
Context
This is an illustrative engineering case based on a realistic orchard deployment pattern rather than a published single-customer reference. It combines common requirements seen in fruit production: frost alerts, leaf wetness monitoring, local weather capture, disease-risk scoring, and delayed synchronisation to a central platform.
Scenario
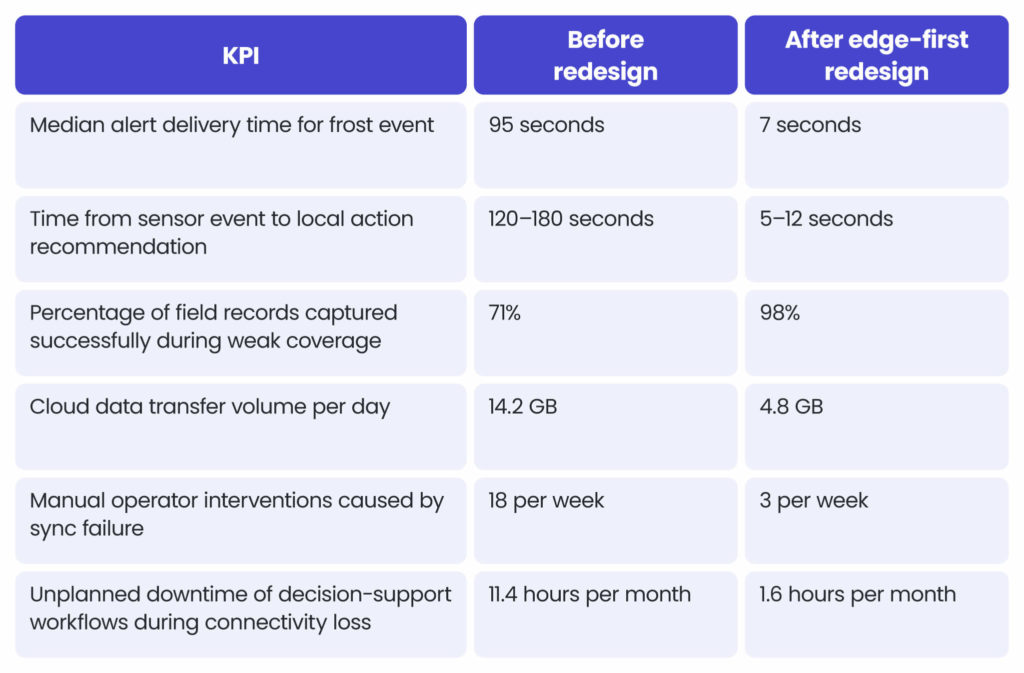
A 120-hectare orchard group operates across 9 separate blocks with mixed connectivity. The previous cloud-first setup relied on central processing for alerts and risk calculations. During spring nights, connectivity instability led to delayed alerts and incomplete field logs.
Target operating metrics
Architecture used
- local gateway per orchard block,
- local rules engine for frost and disease thresholds,
- compact on-device model for event scoring,
- buffered telemetry with store-and-forward transmission,
- central cloud only for historical analytics, seasonal reports, and model updates.
Why have the results improved?
The main gain does not come from “better AI” alone. It comes from moving the decision path to the edge, reducing round-trip transmissions, and sending events instead of continuous raw traffic. This aligns with broader research on edge-enabled agriculture, which consistently reports latency and bandwidth as major constraints in cloud-dependent designs.
Benchmark note
These figures should be treated as a representative delivery benchmark for architecture planning, not as a universal outcome. Real numbers depend on sensor density, topography, network quality, event frequency, and device class.
Common mistakes in agricultural edge AI systems and projects
Seven mistakes that slow down adoption:
- Treating offline mode as a mobile app feature rather than an architecture decision – this usually leads to broken sync, partial data capture, and inconsistent behaviour.
- Pushing raw sensor streams to the cloud by default – an approach that is expensive, fragile, and often unnecessary.
- Using large models that fit the demo board but not the production device – agricultural hardware has thermal, power, and memory constraints.
- Ignoring timestamp drift and ordering problems – in distributed field systems, time quality matters.
- Building alerts without the possibility of local clarification or explanation – operators need to know why the system is issuing a warning.
- Mixing safety logic with general business workflows – these should not share the same dependency chain.
- Skipping field-condition testing – a system tested only on stable office Wi-Fi is not production-ready for agriculture.
Checklist for teams planning edge AI in agriculture
Technical checklist
- Identify critical workflows that must operate offline
- Define the local compute boundary and the cloud boundary
- Select lightweight deployment-ready models
- Add local storage with an audit trail
- Design idempotent sync and retry behaviour
- Handle clock drift and duplicate events
- Expose sync state to operators
- Create fallback rules when the model is unavailable
- Benchmark under weak-signal conditions
- Plan secure remote update and rollback
Product checklist
- Map failure states from the user’s point of view
- Define which screens and workflows remain usable offline
- Show data freshness and sync status clearly
- Avoid blocking task completion because of a missing connection
- Build trust with transparent local behaviour
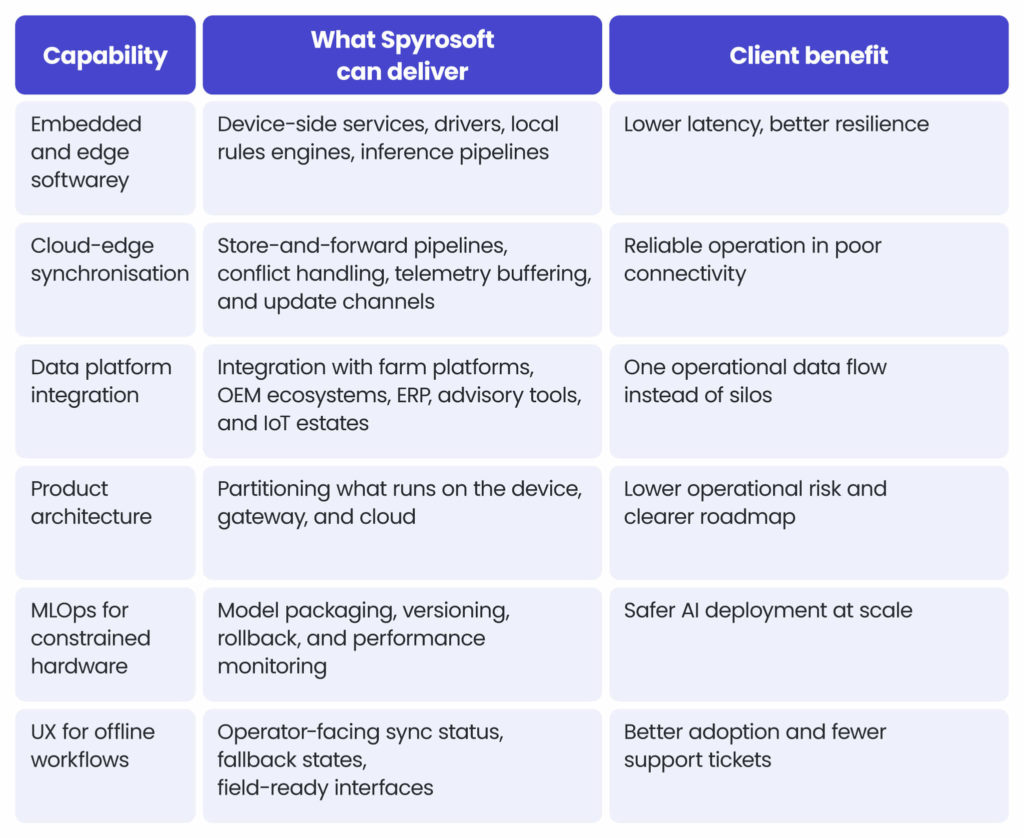
How Spyrosoft supports the area of edge AI application in agricultural practices
Spyrosoft can support edge AI in agriculture and smart farming at the level where many programmes fail: turning fragmented prototypes into production-grade software systems.
What this support can include
Summarising edge AI in agriculture
Edge AI in agriculture is not mainly about putting models on a device. It is about engineering systems that remain useful for precision agriculture when connectivity is weak, partial, delayed, or absent. That means local decision logic, deployment-ready models, durable local storage, resilient synchronisation, and clear product behaviour during failure states.
The market direction is clear. Rural connectivity is improving, but the quality gap remains material enough that agricultural software cannot assume stable cloud access as its operating baseline. Teams that build for intermittent connectivity will deliver more reliable products, stronger adoption, and better commercial outcomes than teams that continue to treat offline resilience as a secondary enhancement.
If you are seeking assistance in building precision agriculture platforms and solutions with offline resilience and intermittent connectivity in mind, reach out to our experts using the contact form below.
Glossary
Edge AI – Artificial intelligence that is executed close to the data source, such as on a machine, controller, gateway, or local server.
Offline-first – A design approach in which the core workflow works without a live internet connection and synchronises later.
Store-and-forward – A communication pattern where data is saved locally and transmitted when connectivity becomes available.
Local inference – Running a trained model on a local device instead of sending data to a remote cloud service for prediction.
Synchronisation conflict – A mismatch created when two versions of the same record are changed independently and later need reconciliation.
Latency – The time delay between an event and the system response.
Quantisation – A model optimisation method that reduces memory and compute load by using lower-precision numerical representation.
Selected sources
OECD, Digital connectivity expands across the OECD, but rural areas are falling further behind, 10 July 2025.
European Commission, Digital Decade 2025: Broadband Coverage in Europe 2024, 16 June 2025.
Gong et al., Edge Computing-Enabled Smart Agriculture: Technical Architectures, Practical Evolution, and Bottleneck Breakthroughs, Sensors, 2025; and Tariq et al., Edge-enabled smart agriculture framework, Results in Engineering, 2025.
FAQ
No. It is equally relevant for weather stations, disease models, irrigation controllers, handheld agronomy tools, mobile farm apps, local gateways, telematics units, and post-harvest monitoring systems.
No. The strongest model is cloud plus edge, with clear ownership of decisions, data, and synchronisation. Cloud is still essential for fleet analytics, retraining, reporting, and integration.
No. Coverage has improved, but rural quality, consistency, and geography-based gaps remain significant. Even where coverage exists, latency variation, coverage holes, and machine mobility still justify offline-first architecture.
Yes, at design time. But that complexity is usually cheaper than operational instability, failed deployments, and user distrust after rollout.
Choose one mission-critical workflow, move its decision path to the edge, implement durable local storage, and add deferred synchronisation with clear operator status.




arrow_circle_rightContact us
Let’s discuss how we can help you with your agritech projects
arrow_circle_right Our articles




