Why large food processing firms are losing control of their data – and what it can cost


Beneath the surface of most large food processing operations lies a quiet structural problem: data flows through dozens of disconnected systems, and no single person or platform holds the full picture. This fragmentation is not merely an IT inconvenience – it is the root cause of slow recalls, failed audits, regulatory exposure, cybersecurity breaches, and millions in avoidable costs. This article traces the chain reaction from fragmented data to its business consequences, explains why the problem is compounding, and outlines what an integrated alternative looks like in practice.
Who should be concerned about fragmented data in large food processing
The challenges described here ripple across the entire food value chain. Different readers will recognise different parts of the problem – but the underlying cause is the same.
- Food processors and manufacturers will find a structured diagnosis of the integration gaps behind batch mix-ups, slow recalls, and audit failures, backed by industry benchmarks and a practical case study with measurable KPIs.
- Agricultural advisors and agronomists will understand why field-level data – fertilisation records, crop protection product applications logged through a crop protection product browser, soil analyses – so often fails to reach the processor’s quality system. The article explains how farm management systems (FMS) close this gap and why advisors play a central role in the data chain.
- Fruit and vegetable distributors will see how data fragmentation at the large food processor level cascades downstream, creating traceability blind spots that expose the entire supply chain to recall risk and regulatory penalties under EUDR and CSRD.
See how our AgriTech team can help you with your data control
Learn more
The root cause of data issues: a patchwork built over decades
No large food processing company set out to build a fragmented IT landscape. It happened gradually, over time. An ERP system was installed in 2008 to manage finance and procurement. A few years later, a separate MES (Manufacturing Execution System) was deployed on the production floor because the ERP could not handle real-time shop-floor data. The laboratory needed its own LIMS (Laboratory Information Management System) to manage test results. The warehouse got a WMS (Warehouse Management System). Sales adopted a CRM. Quality teams built HACCP workflows in yet another tool – or in Excel.
Each system solved a real problem at the time it was introduced. But each was purchased, configured, and maintained independently. Nobody designed the connections between them. The result, in a typical large food processor today, is 8 to 15 systems operating side by side with no shared data model, no common batch identifiers, and no automated data exchange. The same piece of information – a raw material lot number, a supplier certificate, a lab result – exists in multiple versions across multiple systems, with no mechanism to keep them synchronised.
This is not a niche problem. The global Food ERP market reached $4.96 billion in 2024 and is projected to grow at 9.2% CAGR through 2033 – a clear signal that companies are pouring money into enterprise systems. Yet a 2025 review in npj Science of Food confirmed that big data analytics remains underutilised in the food sector precisely because of fragmented data sources and poor cross-sector interoperability (Sharma et al., 2025). Investments are flowing in, but integrations are lagging behind.
This gap between investment and integration is the root cause of everything that follows.
How fragmentation in the large food processing sector creates a chain reaction
Data fragmentation does not produce a single, contained problem. It creates a chain reaction where each consequence amplifies the next. Understanding this cascade is essential to seeing why point fixes – a new dashboard here, a reporting tool there – fail to address the underlying issue.
Link 1: No single source of truth in food processing operations
When systems do not share a common data model, there is no single place where a quality manager, production planner, or operations director can check the full status of a batch – its production history, lab results, associated certificates, current warehouse location, and dispatch status. Instead, people rely on informal knowledge networks: calling a specific colleague who knows which spreadsheet holds the answer, or searching email threads for a forwarded certificate. A 2024 study in Nature Reviews Earth & Environment found substantial global variations in food production data timeliness, granularity, and transparency, underscoring that data accessibility challenges are systemic across the food sector (Kebede et al., 2024).
This is more than an inconvenience. It is a structural vulnerability. When the person who holds critical institutional knowledge is on holiday, changes roles, or leaves the company, that knowledge disappears. The large food processing organisation does not lose a file – it loses the ability to find the file.
Link 2: Traceability breaks down
Without a single source of truth, end-to-end traceability – tracing a finished product from the retail shelf back through processing, incoming inspection, and procurement to the field where the raw material was grown – becomes a manual exercise. Each link in the chain (receiving → production → packaging → dispatch) requires querying a different system, often with non-matching batch identifiers, and manually reconciling the results.
The cost of this breakdown is measured in recalls. Industry data indicates that the average food recall costs approximately $10 million in direct expenses, with companies operating weak traceability systems facing costs that increase by up to 70% per incident. An AMR Research study found that 67% of US and EU food companies surveyed had experienced recalls costing $20 million or more. More critically, the average recall took 42 days to complete, and even then, companies could locate only 43% of affected products. The remaining 57% was either unaccounted for or swept up in precautionary over-recalls – pulling far more product than necessary because the data was not precise enough to narrow the scope.
Regulatory standards make this worse every year. Regulation (EC) 178/2002 already requires full traceability. RASFF (Rapid Alert System for Food and Feed) demands rapid notification. And the upcoming EUDR and CSRD frameworks will impose new data obligations that fragmented food processing systems simply cannot meet without massive manual effort.
Link 3: Paper fills the gaps – and introduces errors
Wherever two systems fail to connect, a human fills the gap with a piece of paper, an Excel file, or an email. Technology cards, quality control protocols, shift reports, incoming inspection records, and cleaning logs – despite significant IT investment, a vast portion of operational data in large food processing still flows through analogue channels. Every manual data entry point can be a source of error: a mistyped batch number, a transposed digit in a weight reading, a missing signature on an inspection form.
These errors are not abstract. They directly contaminate the traceability chain described above. A single mistyped lot number in a receiving log can make an entire batch of raw material invisible to a recall investigation – the system cannot find what it does not know exists.
Link 4: Seasonal peaks expose every data fragmentation weakness
Food processing is inherently seasonal. A sugar beet campaign, a soft fruit processing season, or a vegetable canning operation can see data and transaction volumes spike 5–10 times within weeks. ERP transaction counts surge, WMS processes orders at peak rate, and quality labs run hundreds of incoming inspections daily.
That is precisely where all the weaknesses of the fragmented data structure become apparent. Systems sized for average throughput slow down, queue requests, or crash during the weeks when the business is running at maximum capacity and every hour of downtime means spoiled raw material. Paper workarounds that are manageable at low volume become unmanageable at peak – and the error rate climbs precisely when the consequences of errors are highest.
The supplier gap: where the data chain breaks first
The chain reaction described above begins inside the food processing company. But the data chain actually starts before that – at the farm gate – and this is where it most frequently breaks.
A large fruit or vegetable processor may source from hundreds of agricultural suppliers, each delivering data in a different format: paper delivery notes, scanned PDF certificates, emailed lab results, proprietary portal entries, or EDI messages. There is no single standard for data exchange between farms and food processors. Onboarding a new supplier into the processor’s IT ecosystem – setting up master data, integrating quality documentation, and configuring certificate management – can take weeks.
In seasonal operations, this is a nuisance. A strawberry processor may work with 50 growers during a 12-week campaign. By the time the last supplier is fully onboarded, the season is half over, and the food processor has been operating with incomplete traceability for weeks.
The solution lies in standardised digital interfaces at the farm level. Farm management systems (FMS) that allow growers to submit field records, spray logs (including selections from a crop protection product browser) and harvest documentation digitally before the first delivery arrives can compress supplier onboarding from weeks to days. For agricultural advisors, this means their recommendations and documentation become part of the traceability chain rather than ending in a paper file that never reaches the food processing company. For distributors, it means the products they handle arrive with a digital history attached, reducing their own traceability burden.
Compliance pressure on a fragmented foundation
The regulatory environment is not waiting for food processing firms to solve their integration problems. Multiple compliance frameworks are coming into effect simultaneously, each pulling data from a different part of the organisation – and from different, disconnected systems.
The Corporate Sustainability Reporting Directive (CSRD) requires large companies to report on carbon footprint across their entire value chain, including Scope 3 emissions from upstream suppliers and downstream logistics. The EU Deforestation Regulation (EUDR) demands geolocation data and due diligence proof that specified commodities are not linked to deforestation. Eco-schemes under the Common Agricultural Policy require digitised field-level data. GlobalGAP, IFS (International Featured Standards), and BRC (British Retail Consortium) audits each demand different data, in different formats, at different frequencies.
On a fragmented IT foundation, preparing for any single audit is a resource-intensive manual exercise. Preparing for multiple overlapping audits – which is the reality for any processor selling to European retail – becomes a full-time job for multiple people. According to Aptean’s 2024 Food and Beverage Trends Report, one in four food and beverage organisations struggle to obtain and analyse performance data efficiently. That statistic does not even account for the additional compliance data layers that CSRD and EUDR are now demanding.
The critical insight is that compliance and traceability are not separate problems. They are the same problem viewed from different angles. A company that solves end-to-end traceability – linking field data, incoming inspection, production, quality, and dispatch in a single data architecture – has simultaneously solved 80% of its compliance data challenge. A company that treats each audit as a standalone data-gathering exercise is doing the same manual work over and over, in slightly different formats, for slightly different audiences.
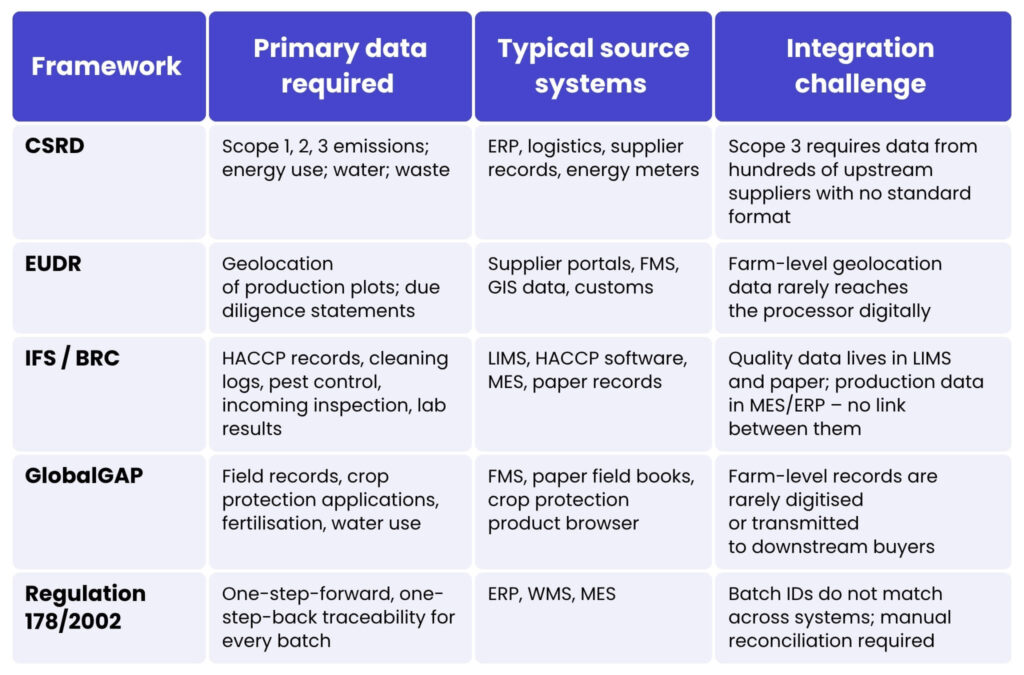
Table 1. Compliance frameworks and their data requirements. Source: Compiled from EU regulatory texts and industry audit requirements.
The people problem beneath the technology problem
Every challenge described so far – fragmented data, broken traceability, compliance overload, cyber exposure – is a technology problem on the surface. But beneath it sits a people problem that makes the technology problem harder to solve.
Large food processing companies are not technology companies. Their core competence is turning raw agricultural materials into safe, consistent food products. Recruiting and retaining IT specialists – software developers, data engineers, integration architects, cybersecurity analysts – is difficult when the processing plant is located 80 km from the nearest city with a technology talent pool. The result is heavy dependence on external IT vendors, system integrators, and consultants. This creates its own risks: vendor lock-in, slow response times, and a persistent gap between business requirements (which internal staff understand) and technical execution (which external teams deliver without full context).
Organisational silos compound the problem. The procurement department does not see quality control data. The production team has no visibility into sales forecasts. The sustainability department cannot access operational data needed for ESG reporting. Each department has its own tools, its own processes, and its own informal data flows. A 2026 analysis of integration maturity in food manufacturing found that most companies operate in a hybrid state of partially automated processes, with information crossing departments through phone calls, emails, and shift-change conversations rather than integrated systems (Food Industry Executive, 2026). Nearly 70% of food companies cite cost as the top barrier to digital transformation – but the companies seeing the strongest returns are those focusing on the organisational and process changes that make technology investment effective, rather than on the technology itself.
This is why “buy a new system” is rarely the right first answer. A more productive starting point is to map the data flows – where information originates, where it needs to go, and where it currently gets stuck or corrupted – and design integration around those flows, using the systems already in place.
What fragmented vs integrated operations in large food processing actually look like
The table below contrasts the operational reality of fragmented and integrated IT environments across the process areas that matter most. It is designed as a quick self-assessment: if the left column reads like a description of your current operations, the right column shows what becomes possible with integration.
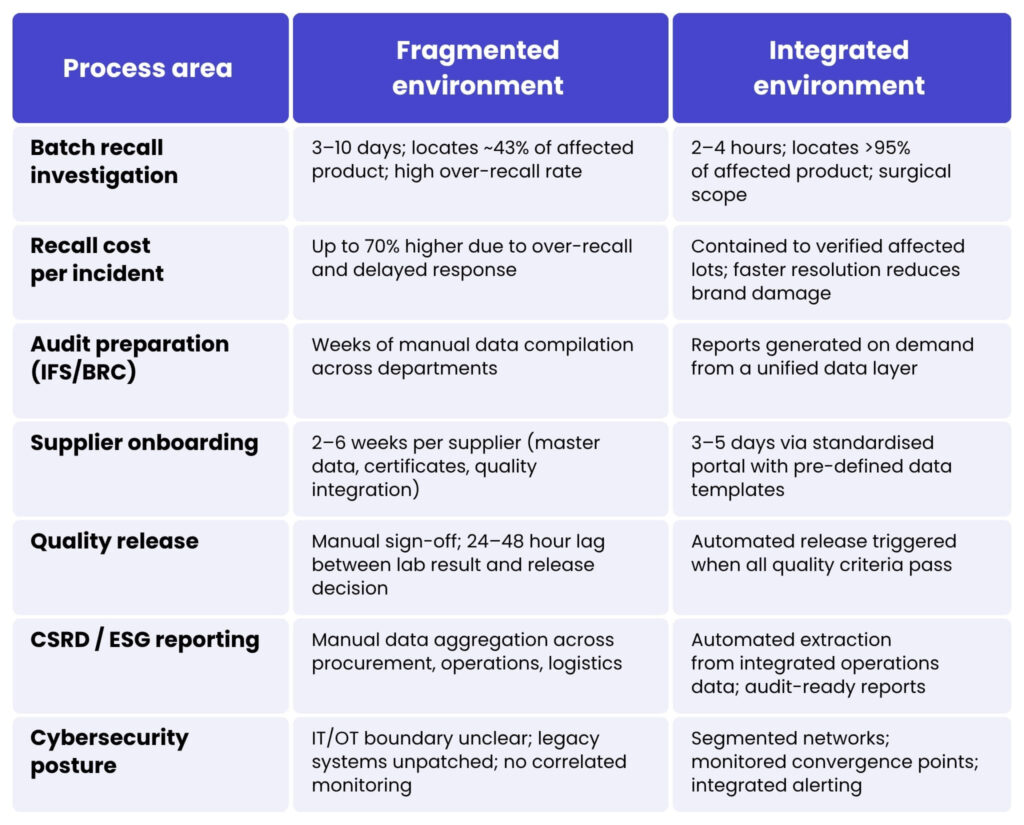
Table 2. Operational impact: fragmented vs integrated IT environment. Sources: AMR Research; Aptean 2024 Trends Report; Food and Ag-ISAC 2025; industry project benchmarks.
How to start: a 5-step integration roadmap for food processing systems
Integration is not a single project – it is a whole programme. But every programme needs a starting point. The following roadmap provides a practical sequence that minimises risk, delivers early wins, and builds the foundation for more ambitious phases later.
- Map your data flows. Before touching any technology, document where critical data originates, where it needs to go, and where it currently gets stuck, duplicated, or corrupted. Focus on the three highest-volume flows: incoming raw material → production → dispatch. Interview the people who actually do the work – they know the workarounds that no system diagram captures.
- Establish a unified batch identifier. This is the single most impactful integration step. Agree on one batch numbering scheme used consistently across ERP, MES, WMS, and LIMS. Without this, every downstream integration effort will require costly translation logic.
- Connect ERP, MES, and LIMS with middleware. Deploy an integration layer that synchronises batch data, production events, and lab results across your three core systems. This does not require replacing any system – it requires building a translator between them. Prioritise event-driven data exchange (e.g., “batch created,” “test result recorded,” “batch released”) over batch file transfers.
- Digitise the supplier interface. Launch a standardised supplier portal with pre-defined data templates for delivery notes, certificates, and quality documentation. For agricultural suppliers, consider FMS-based onboarding that captures field records and crop protection product data digitally at source. This compresses onboarding timelines and closes the traceability gap at the early stage of the chain.
- Segment, scale, and secure. With the data foundation in place, address infrastructure: segment IT and OT networks, migrate capacity-constrained systems to cloud-hosted infrastructure for seasonal scalability, and implement correlated monitoring across IT security logs and OT event data. This phase protects the investment made in steps 1-4.
How Spyrosoft helps large food processing companies regain control
We provide custom software development, strategic consulting, team augmentation, and engineering teams to food processors, machinery manufacturers, agrochemical companies, and agricultural organisations. In the context of the challenges described in this article, our work spans the full integration journey – from initial data flow mapping to production-grade middleware and scalable cloud architecture.
System integration and middleware
Our team builds the integration layers that connect existing ERP, MES, WMS, and LIMS systems without requiring wholesale replacement. This includes API development for legacy systems that lack modern interfaces, event-driven data pipelines, and unified data models that establish the single source of truth described above. The approach is pragmatic: connect what exists, digitise what is still analogue, and replace only what cannot be made to work.
IoT and telemetry platforms
For machinery manufacturers and processors investing in smart production, we design cloud-based IoT platforms for device management, real-time data collection (including ISO-BUS and CAN-BUS telemetry from agricultural machinery), and operational dashboards. A recent project with Corab involved modernising the IT infrastructure and developing a scalable web application for production device management – a pattern directly transferable to large food processing environments.
Cybersecurity and OT/IT architecture
Our experts provide security-by-design consulting for food processors navigating the IT/OT convergence. This includes network segmentation design, vulnerability assessment, and incident response planning tailored to environments where downtime has both food safety and financial consequences.
Digital supply chain and traceability
We develop traceability platforms, supplier portals, and digital passport systems that enable end-to-end visibility across the food supply chain. These solutions support compliance with EUDR, CSRD, and certification requirements (GlobalGAP, IFS, BRC) while reducing the manual burden on quality and compliance teams.
Scalable cloud architecture
For processors facing seasonal capacity constraints, we design and migrate systems to cloud-native architectures that scale elastically – ensuring consistent performance when transaction volumes spike 5–10 times during peak campaigns.
Summary
The IT challenges faced by large food processing companies are not a list of independent problems. They are a chain reaction with a single root cause: data fragmentation across systems that were never designed to work together. This fragmentation destroys traceability, forces paper workarounds that introduce errors, makes every compliance obligation a manual ordeal, and leaves the organisation exposed to cyberattack through the very legacy systems it depends on.
The evidence is clear. Recalls cost millions and take weeks when systems are disconnected – but hours when they are integrated. Ransomware attacks on the sector are doubling year-on-year, targeting legacy infrastructure that remains unpatched because modernisation feels too risky. Regulatory frameworks like CSRD and EUDR demand data that cannot be produced manually from fragmented systems at the speed and precision regulators expect.
The solution is not a new monolithic platform. It is a phased integration strategy: connect existing systems with middleware, establish unified data standards, digitise the remaining analogue gaps, close the supplier data boundary, and secure the architecture. The case study in this article demonstrates that this approach delivers measurable returns – 98% faster recalls, 83% less audit preparation effort, 89% faster supplier onboarding – with a payback period under three years.
Organisations that act now will build a structural advantage in compliance readiness, operational speed, and supply chain resilience. Those waiting will find the cost of inaction compounding with every new regulation, every cyberattack, and every season of peak-load failures.
If you don’t want to wait for the next hurdle, contact our AgriTech team via the form below, and start integrating your food processing environment with tech experts at your side
References
- Sharma, R. et al. (2025). Big data analytics in food industry: a state-of-the-art literature review. npj Science of Food, 9, 42. Available at: nature.com/articles/s41538-025-00394-y
- Kebede, E.A. et al. (2024). Assessing and addressing the global state of food production data scarcity. Nature Reviews Earth & Environment, 5, 295–310. DOI: 10.1038/s43017-024-00516-2
FAQ
This is the most visible symptom of data fragmentation. When ERP, MES, and LIMS each generate their own batch identifiers with no automatic reconciliation, conflicts are inevitable. The solution is integration middleware that maps batch IDs across systems and maintains a single master record – not a new ERP, but a translation layer between existing systems.
With end-to-end digital traceability, a complete recall investigation should take 2–4 hours, not days. The AMR Research benchmark found that companies with fragmented systems located only 43% of affected products – the rest was either lost or swept up in precautionary over-recalls that vastly increase cost.
If your company exceeds the CSRD size thresholds (250+ employees or EUR 50M+ net turnover), you must report on sustainability across your entire value chain. EUDR targets specific commodities (soy, palm oil, cocoa, coffee, rubber, wood, cattle), but many processors and distributors handle soy-derived ingredients or palm oil, making EUDR relevant even for fruit and vegetable businesses.
Start with a farm management system (FMS) that mirrors the data structure advisors already use – field records, fertilisation plans, crop protection product selections via a built-in crop protection product browser – but stores everything digitally. Pilot with a small group, iterate based on their feedback, and then scale. Overnight switches fail; gradual adoption succeeds.
Yes, with middleware. Building an API wrapper around a legacy ERP is typically more cost-effective and lower-risk than full replacement, which can take 18–36 months and cost millions. The key is to treat the legacy system as a data source that needs a modern interface, not as a monolith that must be replaced in its entirety.
Ransomware targeting the IT/OT convergence point. Attackers know that shutting down a food production line creates immediate pressure to pay. In 2025, ransomware incidents in the sector rose 38% year-on-year. The most common entry points are unpatched legacy systems, phishing emails, and poorly segmented networks.
Almost never in practice. The effective approach is integration middleware that connects existing systems and provides a unified data view – a “best-of-breed plus integration” strategy. It reduces risk, preserves institutional knowledge, and delivers a single source of truth faster than a full platform replacement.



arrow_circle_rightContact us
Let’s discuss how we can help you with your agritech projects

arrow_circle_right Our articles


