AI voicebots in the Polish banking sector (part 1)


In the rapidly evolving landscape of digital banking, the importance of effective public speech services cannot be overstated. These services play a crucial role in enhancing customer experience, especially in the context of the Polish banking sector, where customer interaction and communication are paramount. With advancements in artificial intelligence and natural language processing, the capabilities of public speech services have seen a remarkable transformation, offering more intuitive and efficient ways to engage with customers.
The voicebot market in the Polish financial sector is dynamically growing. The customers are now used to talking to virtual assistants and asking them common questions, e.g., about the account’s status. For instance, PKO, one of the oldest Polish banks, has been using virtual assistants for over three years now. In fact, according to their press release, they have as many as 18 different virtual assistants, and as of August 2023, their voicebots alone have already conducted over 25 million conversations with over 9 million customers. Impressive, isn’t it?
With the rapid growth of AI, it’s a good idea to see how AI-related technologies can be implemented in banks and other financial institutions. That’s the main focus of this study and article, which were co-prepared by Kamil Machalica, Senior AI Data Scientist, and Szymon Rożdzyński, DevOps Software Engineer.
Let’s embark on a detailed exploration of various public speech services, particularly focusing on their application in the Polish banking industry. To closely mirror our client needs, resembling those found in contact centre environments, these technologies will undergo testing with sentences tailored to banking scenarios.
These samples will then be enhanced with different noise levels, creating an authentic replication of the audio environment typical in phone conversations with real customers. Our methodology is designed to offer a realistic evaluation of each service’s capabilities, reflecting the complex and demanding nature of customer interactions in banking contact centres.
But before we get to that, there are several possible challenges to discuss.
Challenges with AI voicebots in Polish banking
As we venture into integrating public speech services in the Polish banking sector, we encounter a range of challenges. These hurdles are critical for the development of effective and efficient speech technologies tailored to the needs of Polish customers. Here, we outline some key challenges:
Limited Polish Language Support
A major challenge is the limited support for the Polish language in mainstream public speech services. For instance, AWS Lex, a renowned speech-to-text service, does not support Polish. This necessitates exploring alternative solutions or developing custom models for the complex grammar and pronunciation nuances of Polish.
Constrained Research Resources
Due to the scarcity of external studies and benchmarks on Polish-banking-specific applications, most research in this area is conducted internally. This means institutions often start from scratch, investing significant time and resources in primary research to understand the capabilities and limitations of existing speech technologies for the Polish language and banking requirements. The public cloud services undergo significant changes resulting in research being often outdated.
Time Constraints and Data Limitations in Research
Another significant challenge is the time constraint due to research not being the primary goal of the project. The project had to navigate through this limitation, leading to a dataset that, while not extensive, was sufficient for the project’s immediate needs. However, for more comprehensive insights and accuracy, the research would benefit from more voice examples and additional annotators, beyond the two involved. This would enhance the system’s learning and performance, particularly in a customer-facing environment.
Comparison Metrics – STT and TTS
The evaluation of public speech services is dual-faceted: Speech-to-Text (STT) and Text-to-Speech (TTS). STT focuses on accurately transcribing spoken Polish into text, crucial for understanding customer queries. TTS evaluation is about converting written Polish into spoken words naturally and accurately, essential for clear and understandable customer responses.
In subsequent sections, we will explore each challenge in detail, discussing their impact on deploying public speech services in Polish banking and potential strategies to address them.
Speech-to-Text
A technology known as STT – Speech-to-Text, also known as automatic speech recognition (ASR), converts spoken language into written text. It is particularly useful in applications where speech needs to be converted into a form that computers and intelligent algorithms can process. For example, customer support virtual assistants.
An experiment was designed to test Speech-to-Text (STT) capabilities for evaluating public speech services in the Polish banking domain. In the experiment setup, several key aspects were measured to determine the effectiveness and efficiency of different solutions.
Below is a detailed overview of the experiment setup and what was measured.
Datasets
- Recorded Polish Banking Sentences: A total of 52 sentences specific to banking scenarios were recorded. These sentences included examples like “Czy konsultant może mi pomóc w konfiguracji moich nowych celów oszczędnościowych w aplikacji bankowej?“ (Eng. Can a consultant help me set up my new saving goals in the banking app?).
- Long Conversations: In addition to the sentences, 3 extended conversations between a consultant and a client were recorded. These dialogues simulated real banking interactions, capturing the complexity and variety of customer service scenarios in the banking sector.
- Noise Levels Applied: After recording, these audio samples were subjected to seven different levels of white noise, with Signal-to-Noise Ratio (SNR) values ranging from -20 to 10. This was done to test the robustness of STT solutions in various auditory conditions that might be encountered in real-world settings.
Evaluation metrics
For our evaluation, we prioritised simplicity and clarity in selecting metrics, given the constraints on research time and resources. We focused on two straightforward yet revealing metrics to assess the solutions:
Word Error Rate (WER)
The primary metric for evaluating the accuracy of STT solutions was the WER for audio samples without any added noise. This metric provided a baseline for the best-case scenario performance. WER is a key metric used to evaluate the accuracy of speech recognition systems.
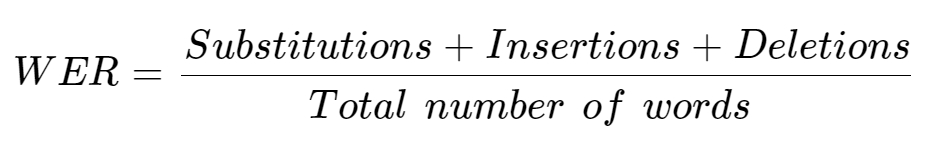
It is calculated as the number of errors (which include substitutions, deletions, and insertions of words) divided by the total number of words spoken, essentially quantifying how often the system misunderstands or misses words. This measure helps in comparing the effectiveness of different speech-to-text solutions, particularly in understanding their reliability in accurately transcribing spoken language.
Execution Time
The time taken for transcription was measured in each of the cloud environments (GCP, Azure, AWS hosted OpenAI Whisper) to avoid biases associated with on-premises processing. This metric helped in assessing the efficiency of each solution.
Solutions tested
In our quest to identify the most effective public speech services for the Polish banking sector, we tested several prominent solutions. Our selection criteria were based on market popularity, language support capabilities, and hosting configurations, ensuring a diverse and comprehensive evaluation.
Google Cloud Platform (GCP) and Microsoft Azure: These were selected as they are the most popular solutions in the market and were available choices in the voice gateway. Their widespread use and reputation in the industry made them prime candidates for evaluation.
AWS hosted OpenAI Whisper: Selected for its support of the Polish language and as a self-hosted solution, providing a contrast to the serverless options of GCP and Azure. This inclusion allowed for a comprehensive comparison between serverless and self-hosted solutions in terms of performance, scalability, and operational considerations.
Results
The experiment aimed to capture a comprehensive picture of how each STT service performed across various dimensions:
Accuracy in different auditory conditions: By applying different noise levels, the experiment assessed how well each service could handle audio quality variations.
Performance in realistic banking scenarios: The use of actual banking sentences and extended conversations provided a realistic testbed for each STT service.
This setup offered a detailed understanding of each service’s strengths and limitations in a real-world banking application, guiding decision-making in the selection and implementation of STT technologies.
Accuracy in different auditory conditions
Before testing different noise levels, present in the real-world scenarios we tested a baseline speech-to-text performance with initial samples that were not affected by artificial white noise. In evaluating the speech-to-text capabilities of various engines for the Polish banking sector, our analysis focused on a dataset consisting of 52 sentences and 3 conversations, mirroring the typical discourse encountered in customer service.
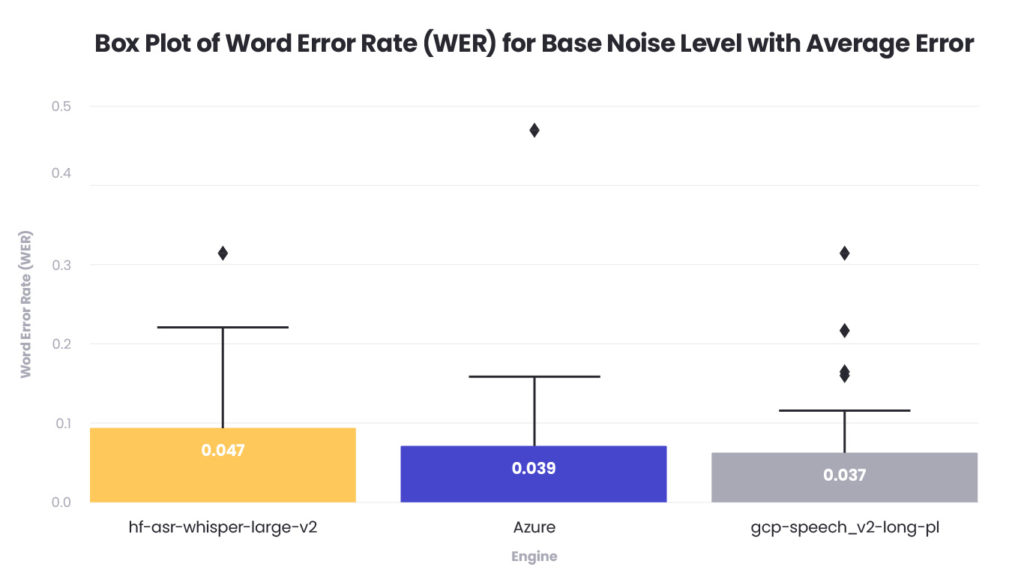
The visual data presented in the accompanying box plot graph illustrates the Word Error Rate (WER) across three selected speech-to-text engines. The first engine, (AWS) hfasr-whisper-large-v2, is indicated in orange and reveals a mean WER of 0.047, with a range suggesting variable accuracy. In contrast, Azure shown in blue and (GCP) gcp-speech-v2-long-pl shown in grey, display a tighter consistency in results with a mean WER of 0.039 and 0.037 respectively.
Word error rate analysis across audio lengths
In the context of our resource and time-constrained internal research for evaluating public speech services in the Polish banking domain, we paid particular attention to the Word Error Rate (WER) in relation to the length of audio samples. This component of our study is essential to gauge how different speech-to-text services handle audio inputs of varying durations, which is a common occurrence in customer service interactions.
Research approach and constraints
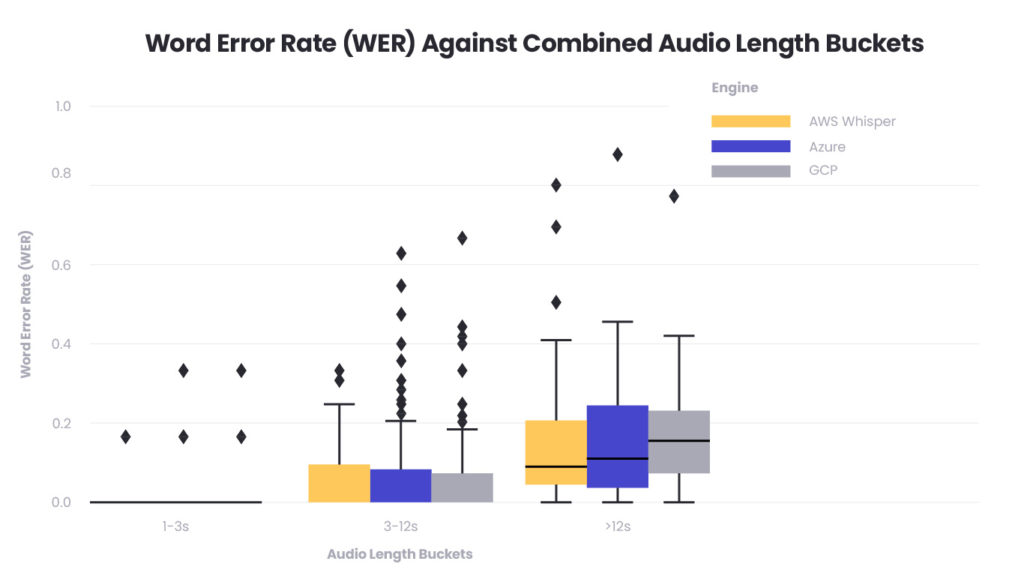
The study involved categorising recorded banking sentences and conversations into three audio length buckets: short (1-3 seconds), medium (3-12 seconds), and long (greater than 12 seconds). Despite the limitations in the breadth and depth of data due to time and resource constraints, the categorisation allowed for a focused assessment of each speech-to-text engine’s performance.
Interpretation and implications
The graph offers a visualisation of how WER is distributed among the different audio lengths for each service. Notably, all services perform relatively well with short audio clips. However, there is a discernible increase in WER for longer audio inputs. One possibility is that longer audio inputs naturally contain more information and thus more potential points of error, including complex sentence structures. Additionally, longer conversations may have more varied vocabulary and syntax, which can test the limits of the trained models, especially if the training data did not sufficiently cover such diversity.
Impact of white noise on speech-to-text accuracy
In the subsequent phase of our internal study, we introduced white noise to our baseline audio records to simulate a more realistic and challenging auditory environment. This step was crucial in determining the robustness of the speech-to-text services against varying degrees of background noise, which is a common issue in real-world telephone conversations within the banking sector. The Signal-to-Noise Ratio (SNR) was employed as a measure of these challenges, with negative SNR values indicating scenarios where noise overwhelms the speech, and positive values representing clearer speech conditions.
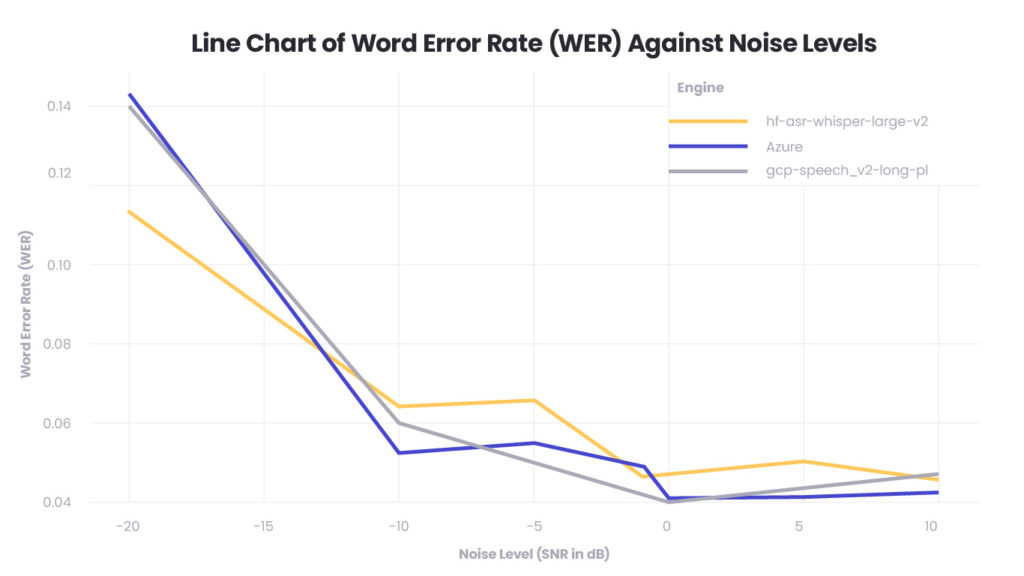
The line chart provided presents the Word Error Rate (WER) of each speech-to-text engine plotted against different levels of noise, measured as Signal-to-Noise Ratio (SNR) in decibels. The engines tested, including AWS Whisper, Azure, and GCP’s speech-to-text service, show how their performance degrades as noise increases, which is expected given that noise can obscure the clarity of speech.
Conclusions
The presence of white noise generally increases the WER across all services, with the most significant impact occurring at higher noise levels (lower SNR values). As the noise level decreases (higher SNR values), the services begin to recover accuracy, suggesting that they have some ability to distinguish speech from background noise up to a certain threshold.
In the comparison of speech-to-text services under varying noise conditions, the results paint a nuanced picture. AWS Whisper exhibited the most robust performance in extreme noise scenarios, particularly at an SNR of -20 dB, suggesting a high degree of resilience in very poor audio quality settings. However, as the SNR increased to levels more representative of typical noisy phone conversations, both AWS and GCP emerged as strong contenders, showing improved accuracy in transcribing speech.
It’s difficult to decisively conclude which of these two—AWS or GCP—provides superior performance based on the limited sample size of our study. Both services demonstrated notable capabilities in handling background noise, and the differences in their performance were marginal. This suggests that for environments with a moderate amount of noise, such as those expected in call centre operations, both AWS and GCP offer viable speech-to-text solutions, with the choice likely depending on other factors such as integration capabilities, cost, and user preference.
It’s pertinent to understand that decibels are a relative unit of measure, particularly when discussing Signal-to-Noise Ratio (SNR). The SNR can vary significantly depending on the power level of the input signal; a higher-powered signal, even with the same amount of noise, would result in a higher SNR value. This variability underscores the complexity of accurately assessing speech-to-text performance across different real-world conditions.
Summary
Our research into the impact of noise on speech-to-text services indicates an area ripe for further development, especially in terms of standardising input signal levels to achieve more uniform SNR measurements. For the scope and requirements of this project, the current level of analysis provided sufficient insights.
Nonetheless, a more nuanced approach to SNR could enhance the predictive accuracy of how these services will perform in the varied acoustic environments of the banking sector’s customer service operations.
In the second part of this article, we will show you another technology that plays a crucial role in developing voicebots (not just in the banking industry) – TTS – Text-to-Speech. It’s a technology that converts written text into speech.




arrow_circle_right Other articles
Pick your next read




arrow_circle_rightContact
