AI voicebots in the Polish banking sector (part 2)


The previous article focused on the technology known as STT. We analysed the effectiveness and accuracy of this technology along with how different factors impact the way it works. In this part, I and Szymon Rożdzyński want to concentrate on the opposite technology that allows intelligent algorithms to convert written text to speech.
Put briefly, TTS is a technology that takes written text as input and generates a corresponding spoken output. TTS is commonly used in applications like voice assistants, accessibility features for visually impaired individuals, audiobooks, and various other scenarios where a natural-sounding voice is needed for communicating textual information.
Let’s have a look at how this AI voicebot technology works in the Polish banking sector.
Text-to-Speech test experiment
In evaluating the efficacy of text-to-speech (TTS) services for the banking industry, we prepared a dataset of pre-written texts. These texts were processed through TTS engines to generate audio outputs, which were then compared against the expected standard of natural human speech. This TTS experiment aimed to critically assess the ability of current technologies to produce speech that is not only comprehensible but also engaging and natural-sounding to the user, which is particularly important for automated systems used in customer-facing industries like banking.
DATASETS
• 11 short sentences: less than 20 tokens. These sentences were designed to represent a variety of customer inquiries and commands commonly encountered in the banking sector.
• 2 long conversations: spanning over 200 tokens. These longer texts aimed to test the endurance and consistency of the TTS services in simulating a natural conversation flow.
EVALUATION METRICS
To measure the performance of TTS services, we used the following metrics:
• Naturalness: this assessed how naturally the TTS output mimicked human speech in terms of tone, tempo, and inflection.
• Punctuation: the ability of the TTS service to correctly interpret and apply the pacing and pauses required by punctuation marks in the text was also tested.
• Comprehensiveness: we checked if the spoken output was clear and fully understandable, thereby effectively conveying the intended information.
• Mean Opinion Score (MOS): the quality of the TTS outputs was evaluated using the Mean Opinion Score, a common subjective quality measurement in audio processing. Recognising the subjective nature of this evaluation, assessments were based on individual perceptions and averaged to yield a general rating for each TTS output.
SOLUTIONS TESTED
Our investigation into text-to-speech (TTS) services for the Polish banking sector continued with the providers previously selected for the speech-to-text (STT) tests: Microsoft Azure and Google Cloud Platform (GCP). These platforms were chosen due to their widespread use and robust support for the Polish language, promising high-quality, natural-sounding speech essential for customer service applications. It’s important to note that we had to exclude AWS hosted OpenAI Whisper from the TTS test, as it is exclusively an STT model and doesn’t offer TTS capabilities.
Our approach was to select three popular voices from each provider, ensuring a broad and comparative analysis across these platforms. For Azure, we opted to include all supported Polish neural voices, as there were only three available. Conversely, GCP offers a wider range of Polish voices, with around 10 options. To maintain a balanced and manageable scope for our study, we selected only three of these voices, aligning with the number tested from Azure.
The chosen voices were:
Microsoft Azure:
- pl-PL-AgnieszkaNeural
- pl-PL-MarekNeural
- pl-PL-ZofiaNeural
Google Cloud Platform (GCP):
- pl-PL-Standard-B
- pl-PL-Wavenet-B
- pl-PL-Wavenet-C
SETUP
Evaluators
The assessment team consisted of two individuals who are native speakers of Polish. Their role was integral to the evaluation process, as they provided expert insights into the naturalness, accuracy, and comprehensiveness of the TTS outputs.
Evaluation Process
The evaluators assessed the TTS-generated audio files, focusing on the metrics of naturalness, accuracy, and comprehensiveness, to determine how effectively each service mimicked human speech.
Rating Scale
The evaluators used a rating scale of 1 to 5 for each metric, with 1 being the lowest and 5 the highest. This scale provided a quantitative measure of each TTS service’s performance, enabling a structured and consistent evaluation process.
Results
The comprehensive evaluation of text-to-speech services has yielded insightful conclusions about their performance in the context of the Polish banking domain. The following results highlight the varied capabilities across different metrics, suggesting that TTS service selection should be voice-specific rather than based solely on the cloud provider.
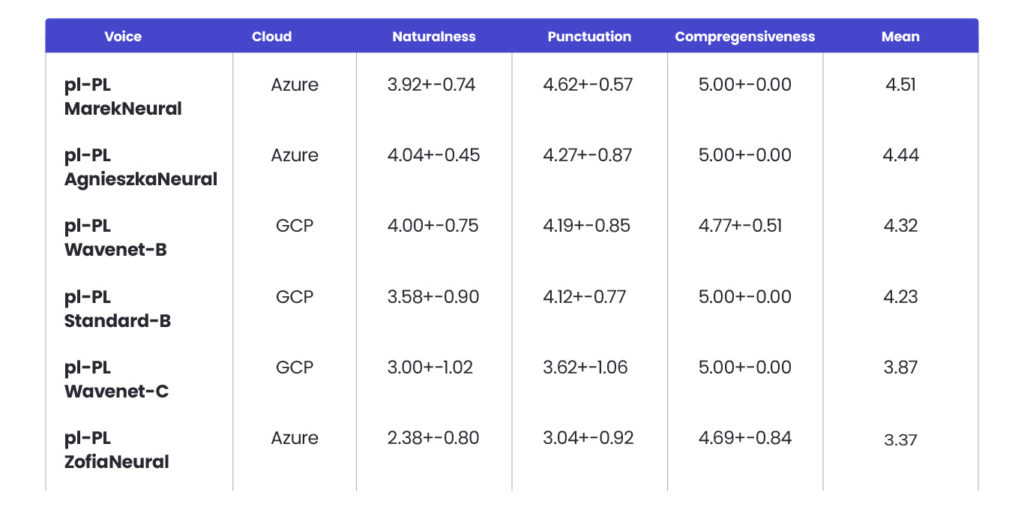
Table 1 – Voices’ comparison – table assessing naturalness, punctuation, comprehensiveness, mean.
NATURALNESS
Results indicate that Azure’s pl-PL-AgnieszkaNeural(4.04 +-0.45), GCP’s pl-PL-Wavenet-B(4.00 +-0.75), and Azure’s pl-PL-MarekNeural(3.92 +-0.74) were the top performers in the naturalness evaluation, with minor differences in their mean scores.
These voices led the field, suggesting they offer the most natural-sounding synthesized speech, closely emulating human voice characteristics. In contrast, the remaining voices exhibited a decline in perceived naturalness, with a notably lower performance from Azure’s pl-PL-ZofiaNeural(2.38+-0.80), which lagged despite Azure having two voices in the top-tier category. This indicates variability in quality within the same provider, with Azure offering both one of the most natural and one of the least natural sounding TTS voices in this evaluation.
PUNCTUATION
Azure’s pl-PL-MarekNeural excelled in punctuation with an average score of 4.62 and the lowest standard deviation, indicating a highly accurate and stable performance and labellers agreement. GCP’s best, pl-PL-Wavenet-B, scored a respectable 4.19, showing proficiency but with a wider variance among samples.
COMPREHENSIVENESS
Both Azure and GCP voices achieved perfect or near-perfect comprehensiveness scores of 5.00, denoting crystal-clear articulation and successful message delivery. It means that overall, the message information is correctly passed to the listener.
Conclusions
It’s time to summarise the whole experiment. In the assessment of public speech services for the Polish banking sector, both Google Cloud Platform (GCP) and Microsoft Azure emerge as strong contenders, offering robust and effective speech-to-text and text-to-speech capabilities.
For text-to-speech applications, it’s crucial to consider the variability in voice performance within the same platform, emphasizing the need for careful selection. Although the pricing of GCP and Azure is comparable, the choice of platform should be based on specific integration capabilities and the existing cloud infrastructure of the banking organisation.
It is also noteworthy to mention the performance of OpenAI’s Whisper model in the realm of speech-to-text services, particularly in scenarios with substantial background noise. Our evaluation highlighted that Whisper excels in environments with very noisy audio, showcasing a high degree of resilience and accuracy. This makes it a valuable option for applications in the banking sector where clear audio may not always be available, such as in phone-based customer service interactions.
However, it’s important to remember that the conclusions drawn from this research could quickly become outdated. The ‘black box’ nature of cloud service providers, including the capacity to update model weights without prior notification, means that the performance of these services can change unpredictably.
This factor underscores the necessity for ongoing monitoring and reassessment of these technologies to ensure they continuously meet the operational needs and standards of the banking industry. Adopting these services should be done with an understanding of their evolving nature and with strategies in place to adapt to potential changes and improvements in their offerings.
AI voicebot case study
This article was mostly about the experiment, but our team is also experienced in implementing voicebot solutions in real-life conditions. For one of our clients, a leading Polish financial institution, we developed a fully functional Polish-speaking AI voicebot from BoostAI. It operates as an intermediary before connecting a customer with an appropriate consultant on the Amazon Connect side.
Would you like to know more about this project? We invite you to read this case study: A powerful integration to transform customer service in Polish banking.
And if you want us to design something similar for your company, our team is at your service. Check out our offering and contact us to discuss your needs.
Text-to-speech (TTS) converts written text into spoken audio. In banking, it supports voicebots, customer service automation, accessibility features, and phone-based interactions where clear, natural communication is essential.
Both Microsoft Azure and Google Cloud Platform offer strong TTS capabilities for Polish. Results show that performance varies by voice rather than provider, so selecting the right voice model is more important than choosing a platform alone.
Naturalness depends on tone, pacing, and intonation. High-quality TTS voices mimic human speech patterns, including appropriate pauses and emphasis, making interactions more engaging and easier to understand.
TTS quality is typically assessed using metrics such as naturalness, punctuation handling, and comprehensibility. The Mean Opinion Score (MOS), based on human evaluation, is commonly used to measure overall audio quality.
Yes, modern TTS solutions provide high comprehensibility and clarity, making them suitable for customer-facing use. However, performance can vary between voices and may change over time, so regular evaluation is recommended.




