How to build enterprise AI agents and multi-agent systems that work in production


Multi-agent systems have quickly become one of the most talked-about ideas in enterprise AI. On slides, the promise is compelling: multiple specialised agents coordinate work, use tools, analyse documents and data, and support faster decisions across the business. In a short demo, everything looks effortless. In practice, that’s usually where things start to get more complicated.
The problem is rarely the model itself. Most prototypes break down much earlier, when they hit production realities: integration complexity, latency, unclear ownership, weak guardrails, and limited observability. That’s the gap you should focus on as an executive. In an enterprise setting, the real question is not whether an agent can produce an impressive answer in a demo, but whether the system can operate reliably, securely, and quickly enough to deliver consistent business value – week after week, not just during a pilot.
That, in practice, is what enterprise AI agent development actually means: you’re building an operating system for decisions, not just generating better paragraphs of text.
How are enterprise AI agents different from simple LLM integrations?
A lot of confusion starts with definitions.
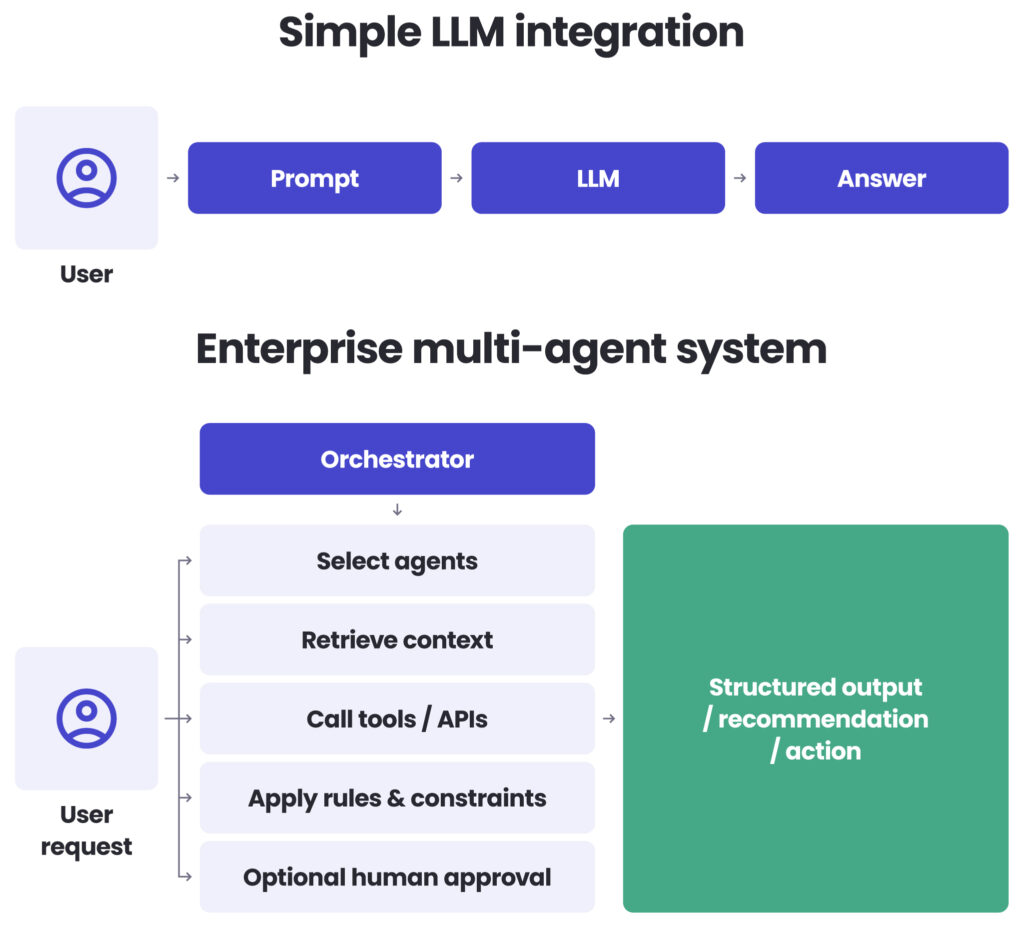
A simple LLM integration generates an answer from a prompt and some context. Think: “search and summarise this document for me.” An enterprise AI agent, especially as part of a multi-agent system, does more: it routes tasks, chooses tools, gathers information from multiple sources, applies constraints, and sometimes coordinates several specialised components before returning an output.
It is the difference between a capable assistant and an operations manager. One can answer questions; the other has to understand the process, talk to multiple systems and people, and still not break anything.
That distinction matters because it changes both cost and delivery risk. If a workflow only needs summarisation, drafting, or question answering over one bounded source, a multi-agent setup may be unnecessary. In many cases, a standard LLM workflow will be cheaper, faster, and easier for you to govern.
Enterprise AI agents and multi-agent systems start to make sense when work requires decisions across systems. For example:
- combining operational data with policy documents,
- investigating issues across ticketing, CRM, and internal knowledge bases,
- coordinating several domain-specific assistants under one execution flow.
The executive takeaway is simple: use multi-agent systems where coordination clearly creates value, not where it only adds architectural complexity.
What actually makes enterprise AI agents useful in production?
The strongest enterprise use cases are usually not about autonomy. They are about controlled execution across fragmented systems. In other words: less “digital employee”, more “disciplined workflow engine.”
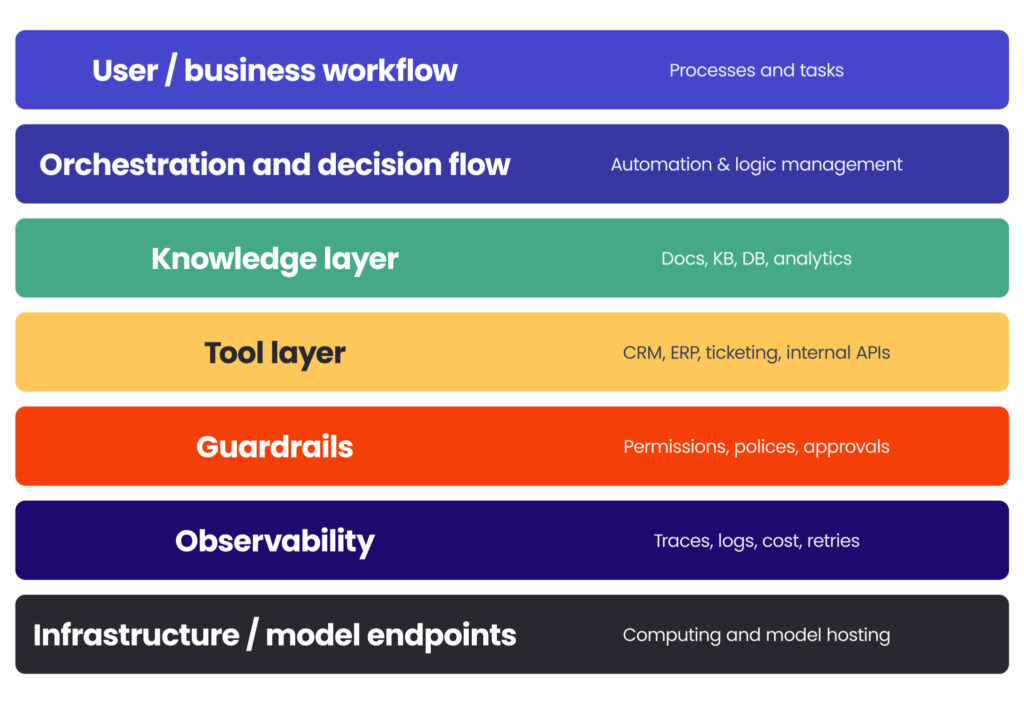
Orchestration is the control layer
This is the part that decides what happens next, which tool gets called, when retries are allowed, and where the boundaries are. Without a clear orchestration layer, multi-agent systems quickly become hard to debug and even harder to trust. Every extra step may add useful capability, but it also adds coordination overhead and latency. You need to design that trade-off upfront, not discover it too late in the process.
Tool integration matters more than model cleverness
In production, agents are only as useful as the systems they can safely access. If they cannot retrieve the right records, query the right data, or trigger the right workflows, they remain polished interfaces rather than business tools. This is why enterprise agent projects often turn into integration projects with AI inside them. In practice, this means you should treat integration as a core part of the solution.
Structured and unstructured data need to work together
Many of the highest-value use cases emerge here. A system may need to interpret a policy document, check a contract clause, and compare it with operational or financial data before recommending an action. That sounds intuitive, but it requires discipline: entity alignment, source separation, context control, and a clear execution path between documents and systems of record.
If you want impressive results without hallucinations, this bridge between documents and data has to be engineered, not improvised. This is where many initiatives succeed or fail.
The architecture must stay adaptable
Retrieval patterns, context-window assumptions, and model choices will evolve. A design that treats today’s implementation pattern as permanent will age badly. The better approach is to keep the architecture modular enough to change retrieval logic, routing rules, or execution paths without having to redesign the whole system.
What is agentic AI architecture in practice (and why performance becomes a system problem)?
One of the most common enterprise mistakes is assuming that response time depends mainly on the model.
It does not.
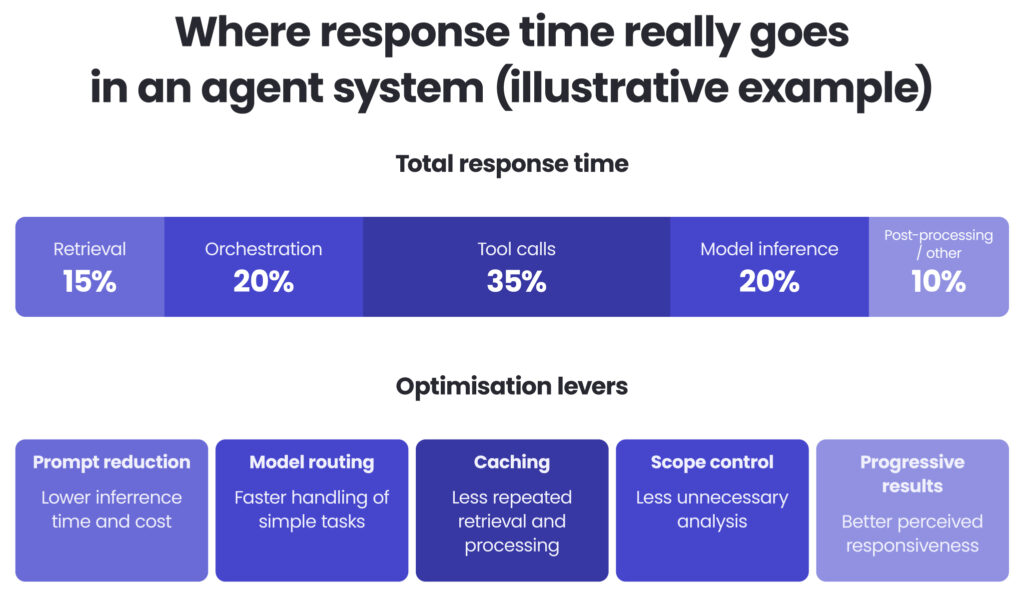
Performance in multi-agent systems is usually the sum of several layers: retrieval, orchestration, tool calls, model inference, and post-processing. That means performance issues rarely disappear with a single optimisation. They improve when you look at the whole execution path and optimise it end-to-end.
The highest-impact levers are usually practical rather than complex:
- reducing prompt size,
- routing simple tasks to smaller or cheaper models,
- caching repeated computations,
- avoiding unnecessary analysis for low-complexity requests,
- returning progressive results instead of making users wait for one final output.
This point matters more than many teams expect. UX is part of the performance story. Users don’t just look at response time – they judge whether the system feels responsive and predictable. Intermediate updates, partial outputs, or visible step-by-step execution can significantly improve trust, even before deeper performance gains are in place. If you want users to trust the system, responsiveness is just as important as raw speed.
In one enterprise rollout, the biggest speed improvements did not come from changing the model alone, but from coordinated optimisations across prompts, routing, caching, and orchestration. That is usually how production systems improve: through disciplined tuning of the whole stack.
Think of the agent platform as a restaurant: the model is just the chef. Retrieval, orchestration, tools, and UX are the kitchen, service, and billing. If those fall apart, the quality of the food stops mattering very quickly.
What are the risks of AI agents in production (and how do you mitigate them)?
A system that makes decisions across tools and data sources cannot be treated like a chatbot with better branding.
In production, your teams need to know:
- what the agent planned,
- which tools it called,
- which sources it used,
- how long each step took,
- what it cost,
- where it failed,
- and why it returned a given recommendation.
This is where observability becomes critical. It’s not a compliance add-on, but a core operating requirement.
In regulated environments, it’s also how you support compliance – through clear audit trails of what the system saw, did, and recommended. When a multi-agent system behaves unexpectedly, decision traces act like a flight recorder. They help teams diagnose routing mistakes, poor tool selection, retry loops, missing constraints, and cost anomalies before those issues start to undermine trust.
The same applies to guardrails. The main production risks are well known: prompt injection, data leakage, tool misuse, and uncontrolled escalation.
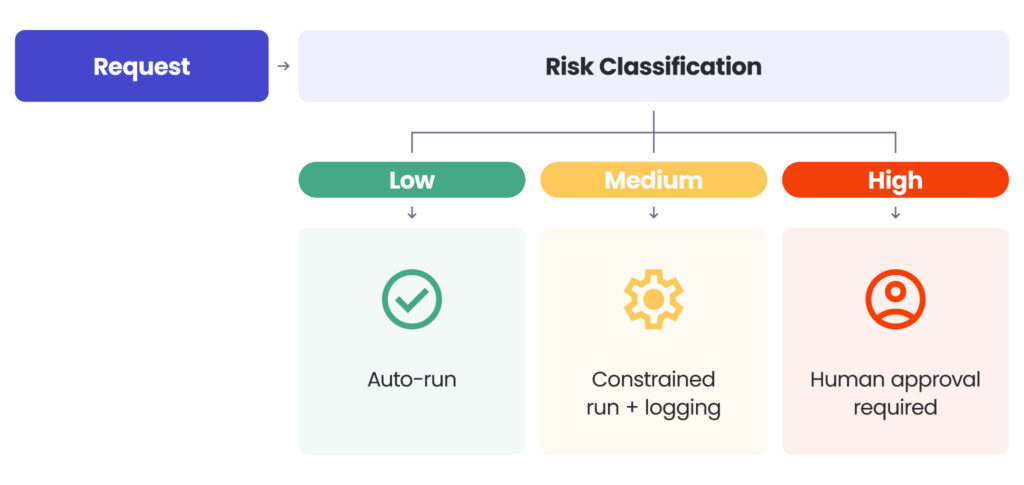
The right response is not to avoid agents, but to design execution based on risk levels:
- low-risk tasks can run automatically,
- medium-risk tasks should run under tighter constraints with full auditability,
- high-risk tasks should require human approval.
A useful rule is simple: if you cannot explain why the system took a given action, it is not production-ready. That holds technically, operationally, and from a governance standpoint. “We asked the model nicely” is not an audit strategy.

Each step logs: trace, inputs, tool response, latency, cost, policy checks.
Common mistakes in agent development
Most enterprise agent failures do not come from weak models, but from predictable delivery and architecture mistakes.
Some of the most common ones include:
- treating an agent as “just prompts” instead of a production system with clear ownership, controls, and telemetry,
- launching a broad platform before proving one dominant end-to-end workflow with measurable success criteria,
- adding components without measuring their impact on execution-path latency, failure modes, and integration overhead,
- deferring observability until after users lose trust and issues are already visible in production,
- allowing tools to run without strict permission boundaries, policy gates, and audit trails,
- assuming platform constraints are implementation details rather than delivery risks that change performance and timelines,
- letting scope expand without formally re-baselining timelines, costs, and capacity.
The pattern behind these mistakes is simple: teams focus on model behaviour first and operating discipline second. In practice, you’ll get better results if you reverse that order from the start.
See how AI can transform your business
Schedule an AI advisor
How do you scale from Proof of Concept to enterprise deployment?
Many enterprise agent initiatives become unstable long before go-live, not because of model quality, but because of delivery design. Once those common mistakes are avoided, scaling becomes much more manageable.
Run discovery before making hard commitments
If the system relies on unfamiliar platforms, preview features, or complex integrations, a short feasibility phase is essential. Benchmark latency, validate rate limits, and build a minimal end-to-end prototype in the target environment. Identify risks early and assign ownership – this is far less costly than dealing with architectural friction during delivery.
Start with one bounded workflow
A common mistake is trying to launch a full platform too early: multiple agents, document intelligence, analytics, admin features, governance controls, and broad integrations all at once. The better approach is to prove one dominant workflow first, then scale. That produces faster validation and a clearer ROI signal.
Treat platform constraints as first-class delivery inputs
When a client mandates tools, cloud patterns, or framework choices, those decisions change performance, complexity, and timeline. They should be priced into the plan explicitly, not treated as neutral background conditions.
Control scope formally
Multi-agent initiatives become fragile when scope expands without adjusting time and capacity. Formal change control is what keeps enterprise delivery reliable.

Where ROI really comes from
What executives really need is to know what improves, not another abstract promise about AI transformation.
For multi-agent systems, the most useful ROI metrics are operational:
- reduced investigation time,
- faster compliance or review cycles,
- fewer manual handoffs,
- lower cost per analysis,
- quicker access to decision-ready information.
That is why build-vs-buy should also be framed operationally.
Buy when speed matters most, integrations are limited, and the goal is to validate a narrow use case. Build or heavily customise when governance, deep system integration, and multiple strategic workflows become core to the operating model.
Most enterprises land in the middle: a hybrid setup that combines vendor components with an enterprise agent platform layer for internal orchestration, control, and governance.
What this looks like in practice
In practice, successful enterprise teams treat AI agents as production systems, not prompt workflows.
That means focusing on three things from the start: architecture and integration, performance and cost control, and governance by design. The goal is not more autonomy for its own sake. It is reliable execution across real enterprise systems, with clear operational boundaries and measurable outcomes.
This is the approach Spyrosoft brings to enterprise AI delivery.
Conclusion
The future of enterprise AI will likely involve ecosystems of specialised agents. But the organisations that benefit first will not be the ones with the most sophisticated demos. They will be the ones that treat multi-agent systems as production software: bounded, observable, integrated, and governed.
The practical path is not complicated. Start with one high-value workflow. Design observability and guardrails from day one. Prove reliability before scale.
That is what turns agentic ambition into business value – and what ensures a great demo can become a reliable production system.
At Spyrosoft, we work with organisations to design and deliver production-ready AI systems – from early discovery and architecture design to integration, optimisation, and governance. If you want to explore how this could look in your environment, let’s have a conversation.
FAQ: Enterprise AI agents and multi-agent systems in production
Enterprise AI agents work by combining orchestration, data access, and decision logic into one execution layer. In practice, enterprise AI agents rely on structured coordination rather than raw model intelligence. They integrate multiple tools, retrieve enterprise data, and follow predefined execution paths to complete complex workflows reliably. This is how artificial intelligence moves from isolated outputs to consistent operational impact.
AI assistants typically respond to prompts, while enterprise AI agents represent coordinated systems that can plan, act, and interact with multiple services. Enterprise AI agents work across systems, not just within a single interface. They integrate tools, apply constraints, and execute tasks end-to-end, which makes them suitable for complex workflows rather than simple question answering.
Autonomous agents make sense when decisions span multiple systems and require coordination. Enterprise AI agents rely on orchestration to manage dependencies, risks, and execution order. For simpler use cases, lightweight AI automation is often more efficient. The key is matching the solution to the complexity of the workflow rather than defaulting to autonomy.
Enterprise AI agents integrate through APIs, data pipelines, and controlled access layers. They rely on secure connections to enterprise data sources and use agent tools to retrieve, update, or validate information. This integration layer is critical, as enterprise AI agents work only as well as the systems they can safely access and coordinate.
The main risks include lack of observability, uncontrolled tool usage, and weak governance. Enterprise AI agents rely on traceability to show how decisions were made, which is essential for both trust and compliance. Without visibility into agent performance, even well-designed systems can fail silently or behave unpredictably in complex workflows.
Reliability comes from treating enterprise AI as a system, not a model. Enterprise AI agents work best when orchestration, monitoring, and guardrails are designed from the start. This includes clear execution paths, policy enforcement, and continuous tracking of agent performance across all steps of a workflow.
Agent tools are what allow AI agents to move beyond text generation. Enterprise AI agents rely on tools to interact with databases, APIs, and business applications. This is how AI agents integrate into real operations and execute complex workflows instead of just describing them.
AI automation improves consistency and efficiency, but it must be carefully controlled. Enterprise AI agents rely on balanced orchestration to maintain strong agent performance. Over-automation can introduce latency or errors if workflows become too complex, so optimisation across the full execution path is essential.




arrow_circle_rightContact us
Let’s discuss your AI use case

Tomasz Smolarczyk
Director of Artificial Intelligence
arrow_circle_right Our articles





