NVIDIA’s L2++ to L4 strategy: the platform, the architecture, and what’s already in production


If you’re evaluating NVIDIA DRIVE as a platform decision, not just a component choice, this article gives you the system-level view. We cover what L2++ actually delivers in production today, how the Hyperion platform scales from L2++ to L4 on a consistent software and integration architecture, and why the choices that look like constraints are actually deliberate strategy.
L2++ is already in production
In Q1 2026, Mercedes-Benz started series production of the new CLA. It’s a consumer car that navigates point-to-point across motorways, suburbs, and dense urban traffic – with no lidar, no pre-built HD maps, and a single chip drawing under 45W.
That’s not a concept vehicle or a pilot programme – it’s in production today.
L2++ is a widely used industry term for highly advanced consumer driver assistance, and NVIDIA’s implementation of it is a fundamental rethink of how autonomous driving software is built. And it scales directly to the L4 robotaxis that Uber and Mercedes-Benz plan to operate in San Francisco and Los Angeles by H1 2027.
The CLA earned Euro NCAP’s Best Performer award for 2025. It runs on NVIDIA Hyperion – a scalable reference platform designed to take the same architecture from L2++ all the way to L4. The L4 configuration, Hyperion 10, runs on roughly 8× the compute (dual Thor SoCs at 1,000 INT8 TOPS each), adds lidar, and is already committed to multiple OEM programmes.
Same platform, but more compute, more sensors, and a different liability model.
What L2++ actually delivers
Traditional L2 maps detected objects to predefined responses. NVIDIA’s L2++ works differently. It navigates point-to-point through urban environments, handles dynamic obstacles with context rather than reflexes, executes unprotected turns, and tracks multiple actors simultaneously.
In a live demonstration through San Francisco, the system spotted double-parked delivery vehicles and worked out the gap and timing to get through – it didn’t just flag an obstacle. It yielded when a vehicle reversed towards it, avoided an open car door, and completed an unprotected left turn while managing oncoming traffic and a crossing pedestrian at the same time.
In normal conditions, the end-to-end neural stack generates the active trajectory most of the time. The classical stack runs alongside it as a continuously enforced safety boundary, not a fallback waiting for the AI to fail.
The no-lidar, no-HD-map decision is deliberate architecture, not a cost cut.
Eliminating lidar cuts the bill-of-materials enough to deploy this in a mainstream consumer vehicle. Dropping pre-built HD maps removes geographic fencing entirely – the system works in cities that have never been pre-mapped. Instead, the classical stack builds an HD map on the fly from raw camera input and navigation data: lane lines, connectivity, direction-of-travel, traffic light rules, and turn-lane associations – all generated on board, at runtime.
The driver interaction model is just as intentional. The driver can apply steering input mid-manoeuvre and the system doesn’t disengage. It treats the input as cooperative, keeps operating, and resumes full authority when you take your hands off the wheel. There’s no engage/disengage cycle; the driving software stays active throughout.
This L2++ configuration is already in production in the Mercedes-Benz CLA. Jaguar Land Rover follows from 2026, with further OEM programmes rolling out across the platform through 2028.
The architecture that makes it work
Hyperion
At the centre of NVIDIA’s automotive offer is DRIVE AV: the full autonomous driving software stack. Hyperion is the production-ready reference platform built around it, combining validated compute hardware, a qualified sensor suite, and a defined integration boundary against the host vehicle. OEMs can build directly on Hyperion or work with NVIDIA on a fully customised implementation – as Mercedes-Benz, JLR, and Lucid are doing.
Three configurations share one architectural lineage:
| Configuration | Compute | Cameras | Radar | Lidar | Level |
| CLA (L2++) | 1× Orin – 254 TOPS | 10 | 5 | – | L2++ |
| Hyperion 8 | 2× Orin – 508 TOPS | 12 | 9 | 1 | L4 development |
| Hyperion 10 | 2× Thor – 2×1,000 TOPS | 14 HD | 9 | 1 | L4 production |
The shared architecture is what makes the L2++ to L4 path realistic. An OEM that has already validated sensor mounting, time synchronisation, calibration, and harness routing for Hyperion 8 doesn’t need to redesign the integration for Hyperion 10. Same E/E architecture, but with scaled compute and sensors.
DRIVE OS
Beneath DRIVE AV sits DRIVE OS – TÜV SÜD-certified to ISO 26262 ASIL D, ASPICE-compliant, and aligned with ISO/SAE 21434 for cybersecurity engineering. It provides a deterministic, certifiable execution environment for the AV stack and exposes the heterogeneous compute of Orin and Thor to higher-level software.
The underlying silicon goes further: DRIVE AGX Orin holds its own ISO 26262 ASIL D certification at chip level, which significantly reduces the safety argumentation burden for OEMs building on the platform. Thor is on the same certification path.
The parts that matter most at integration time:
- Hypervisor with guest OS isolation. NVIDIA’s Type-1 hypervisor runs QNX and Linux simultaneously in isolated partitions: QNX as the ASIL-D certified safety partition, Linux as the compute partition running the AI/ML stack, DriveWorks, and TensorRT. This lets you host ADAS, IVI, cluster, and DMS workloads on the same SoC without compromising the safety case.
- NvMedia and NvStreams. NvMedia loads camera frames straight into GPU memory with no buffer copies and no added latency. NvStreams extends that zero-copy guarantee across the GPU, DLA, PVA, and image signal processors. The result is a deterministic perception pipeline, which is a precondition for any credible ASIL argument.
- Heterogeneous redundancy. Critical workloads can run across different processor types – a primary perception path on the GPU and a redundant lighter-weight path on the DLA, reducing the risk that a single silicon fault eliminates the function entirely.
- CUDA and TensorRT continuity. The same APIs run from DGX cloud training through to in-vehicle inference. Models deploy to the vehicle without re-implementation, which keeps training and inference behaviour consistent.
The dual stack and the Safety Force Field
DRIVE AV runs two parallel driving stacks at the same time, with a mathematically defined safety override on top of both:
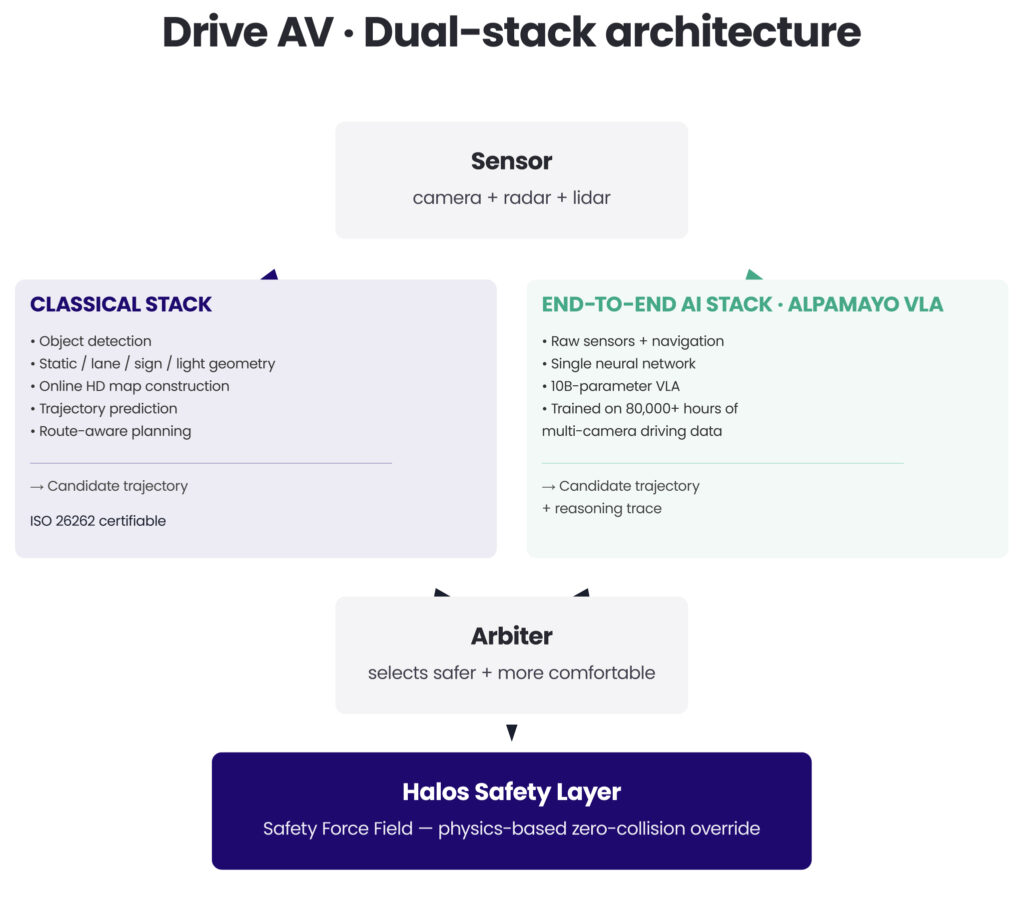
The classical stack gives you a certifiable safety envelope – formally analysable, traceable to ISO 26262 work products. The end-to-end stack handles the long tail of real-world edge cases that rules can’t enumerate. Both stacks produce candidate trajectories simultaneously. An arbiter picks the safer and more comfortable one, with the SFF providing the hard outer bound.
Halos: safety as a cross-layer property
Above DRIVE OS and the dual stack sits Halos. It’s NVIDIA’s umbrella safety framework, organised across three levels:
| Level | Scope |
| Technology | ASIL D SoC + DRIVE OS + Hyperion (platform); safety data APIs, modular + E2E stack (algorithmic); curated datasets, automated evaluation, data flywheel (ecosystem) |
| Development | Design-time safety constraints in model training; deployment-time runtime monitors; validation-time replay and simulation at scale |
| Computational | DGX (cloud training) + OVX (Omniverse simulation) + DRIVE AGX (vehicle deployment) – all three form part of the safety system; validation evidence is generated across all three |
One of its applications is the Safety Force Field (SFF), which sits downstream of both stacks as the last override before actuation. It’s a physics-based policy layer that computes a zero-collision envelope frame-by-frame. It’s mathematically deterministic (braking and steering evaluated jointly, not separately) and it overrides any upstream output that would breach the envelope.
Safety here isn’t bolted on at integration time. It’s a property of the cloud-simulation-vehicle triad. If you train off-platform and import models without OVX re-validation, the safety case breaks.
A decade of compute growth
The DRIVE platform has grown roughly 500× in TOPS at single-chip level since 2015 – from the original Drive PX (~2 TOPS, Maxwell) through Xavier (30 TOPS, Volta + DLA, 2017), Orin (254 TOPS, Ampere, 2022), to Thor (1,000 INT8 TOPS / 2,000 FP4 TOPS, Blackwell, 2025).
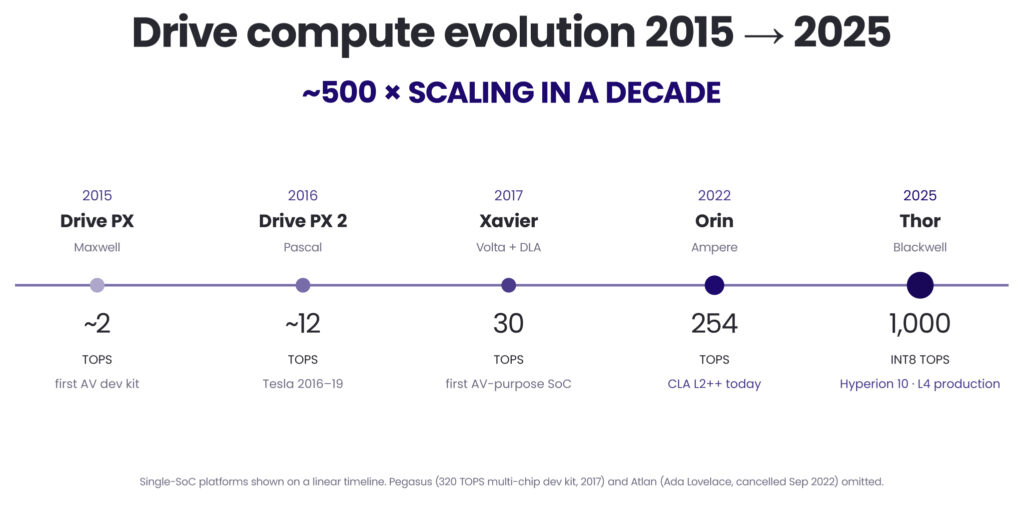
Two moments stand out. Xavier (2017) was the first NVIDIA chip designed from scratch for production AV. It introduced the DLA, a fixed-function neural-network accelerator separate from the GPU. Atlan, the planned Ada Lovelace-based AV chip announced in 2021, was cancelled in September 2022 in favour of jumping directly to Thor (Blackwell) – a clear signal of how fast the post-Ampere AI compute roadmap moved.
Thor (2025) consolidates all vehicle compute domains onto a single SoC: autonomous driving, parking, driver and occupant monitoring, instrument cluster, infotainment, rear-seat entertainment. It pairs an ARM Neoverse V3AE CPU with a Blackwell GPU, integrates a Transformer Engine for LLM- and VLA-class workloads, and uses NVLink-C2C for chip-to-chip bandwidth in dual-Thor Hyperion 10 configurations. Hardware partitioning keeps the ASIL D ADAS workload and the QM-rated infotainment workload isolated on the same die.
Thor makes centralised, software-defined-vehicle compute possible. It replaces the distributed ECU topology that’s defined automotive E/E architecture for decades. That transition is its own multi-year programme, separate from the AV stack running on top.
L4: what’s committed and when
Before the timelines, the definition matters. L4 means a system that handles all driving tasks within a specific operational design domain – bounded geography, defined conditions, no human required.
NVIDIA’s commercial roadmap skips L3 entirely. The reason is practical: L3 requires the driver to be ready to take over instantly while not actively supervising. That handoff liability problem has kept most OEMs away from it.
Honda’s world-first L3 approval in 2021 covered just 100 lease-only vehicles in Japan. Mercedes-Benz’s Drive Pilot is one of the very few OEMs globally to have taken on L3 liability. NVIDIA positions L2++ and L4 because both have clean liability models – L2++ keeps the human actively in the loop, L4 takes full responsibility within a defined ODD. L2++ and L4 both have clear answers to ‘who’s responsible’. L3 doesn’t, and that’s why NVIDIA skips it.
What L4 requires architecturally beyond L2++:
- Redundant compute: 2× Thor rather than 1× Orin
- Lidar added as an independent perception validation path
- Safety-certified HD maps with a manual verification step
- Halos OS as the in-vehicle safety operating system layer
Committed deployments with named partners and public timelines:
| Partner | Vehicle / role | Timeline |
| Mercedes-Benz | S-Class – premium robotaxi | Announced January 2026 |
| Uber | Fleet operations – LA + San Francisco | H1 2027 |
| Uber | Global expansion – 28 cities, 4 continents | 2028 |
| Stellantis | K0 Van + STLA Small – 5,000 units | 2028 SOP |
| BYD, Geely, Isuzu | L4 vehicles on full NVIDIA stack | 2025+ |
| Nissan | L4 robotaxi (Hyperion hardware + Wayve software) | Tokyo Uber pilot, late 2026 |
| JLR | All new vehicles on DRIVE platform | From 2026 |
| Lucid | Midsize EV lineup – DRIVE AGX Thor | Late 2026 |
More than 20 of the top 30 global EV makers have adopted DRIVE Orin. Every OEM on the platform feeds the shared data flywheel. It’s a network effect where platform capabilities compound regardless of which partner grows fastest.
AI-driven development in the innovation driven sector
Find out how we can help you
What this means for you
Hyperion gives OEMs and Tier 1s a validated path from today’s L2++ production reality to committed L4 deployments, on a consistent software and integration architecture. The L2++ choices that may look like limitations (no lidar, no pre-mapped HD maps, online map construction, cooperative driver interaction) are the conditions that make mainstream deployment possible.
Understanding the platform at this level matters most when you’re deciding whether to build around it, integrate into it, or validate against it. That decision gets harder (and the safety obligations get more complex) once AI-based components enter the stack.
Part 2 of this article series covers exactly that: the AI leap behind Alpamayo VLA model, the data flywheel, the real L4 timelines, and what Spyrosoft’s hands-on work with the stack means for your integration programme.

If you’re already evaluating NVIDIA DRIVE integration and want a technical conversation about where your programme sits, get in touch with our automotive team via the form below.




arrow_circle_rightContact us
Get in touch to discuss your needs

arrow_circle_right Our articles



