Object detection in large panorama images


Panoramic photos are becoming increasingly popular in today’s world, especially when exploring cities using tools like Google Street View. With the rapid development of computer vision techniques, it is now possible to build state-of-the-art object detection models for panoramic photos to help identify and locate different objects in them.
In this article, we will explore how to build object detection computer vision models for panoramic photos using a SAHI (Slicing Aided Hyper Inference) framework and discuss examples of where such models can be used. We will focus on identifying and detecting traffic signs and other road network infrastructure features.
The challenges of working with panoramic images
Panoramic images of cities, like in Google Street View, present unique challenges when building object recognition and detection models. One of the most significant challenges is the large size of the images. These images can be thousands of pixels wide, making it difficult to process them efficiently.
Another challenge that comes with building object detection computer vision models for panoramic photos is the small object size relative to the overall image resolution. In some cases, the objects in the panorama images can be less than 0.1% of the whole image area, making them very difficult to detect, identify and analyse.
When the objects are small, the resolution of the images may not be high enough to provide the level of detail required for accurate object detection or image classification. Additionally, the small size of the objects can make it difficult to distinguish them from the image’s background, which can further complicate the detection procedure. Analysing specific image regions can help in isolating and identifying small objects from complex backgrounds, improving detection accuracy.
Computer vision modeling for detecting objects
Building object detection models for panoramic photos requires several key steps. First, we had to obtain a dataset of panoramic photos that we then used to train our model.
Data preparation and image classification
Preparing data is a crucial step in building an accurate and effective object detection model for panoramic photos. This involves gathering and labelling a large set of panoramic images that will be used to train the object detection model. In this particular case, a few hundred panoramic images were hand labelled with traffic signs, traffic lights, fire hydrants, road infrastructure features, and other relevant labels.
Hand-labelling images is a time-consuming technique, but it is essential for training an accurate object detection model. Labelling each object in the image allows the model to identify and accurately classify each object when presented with new images. Additionally, the labelled data enables the model to classify images by assigning them to predefined categories based on the objects present.
Some statistics on images and bounding boxes for our dataset:
- Train set:
- 500 panorama images
- 1998 bounding box annotations
- Test set:
- 250 panorama images
- 1045 bounding box annotations
The datasets were highly imbalanced, as seen in the figures below. Only 29 instances of speed-limit signs can be seen in the training dataset. Additionally, over 80% of the bounding boxes were smaller than 50×50 pixels. This is a very challenging setting for all object detectors.
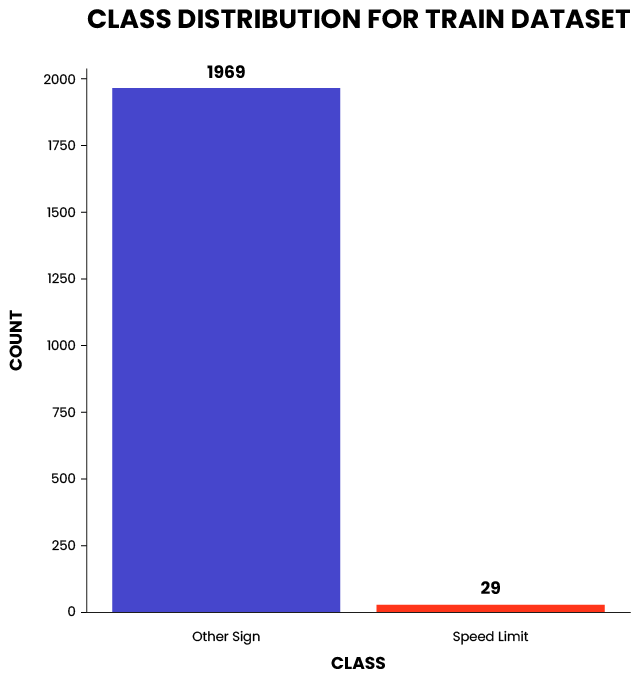
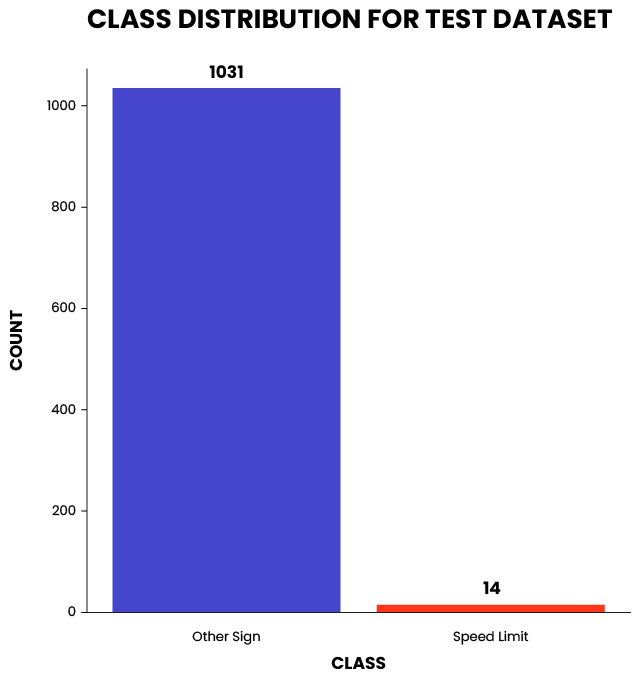
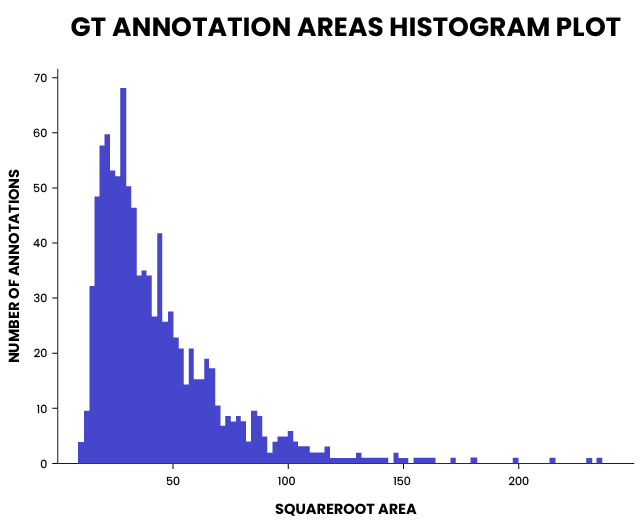
The datasets were highly imbalanced, as seen in the figures below. Only 29 instances of speed-limit signs can be seen in the training dataset. Additionally, over 80% of the bounding boxes were smaller than 50×50 pixels. This is a very challenging setting for all object detectors.
As you can see, this was a very small sample of data – usually, we deal with thousands or even hundreds of thousands of images. However, given the large size of the panoramas and the very small size of the objects we were labelling, it took over 3 man-days to label those 750 images.
For large-scale production models, when thousands or millions of images need to be labelled, we recommend automating this process with transfer learning and quick iterations.
The YOLO family model
In our case, we opted for using the YOLO family of models. YOLO is an object detection model family that has recently gained popularity. As deep learning models and deep learning networks, YOLO and its variants are widely used for object detection tasks. YOLO stands for “You Only Look Once”. We used YOLOX, which is an upgrade to the original YOLO model. YOLOX is based on a convolutional neural network architecture and is a type of neural network optimized for object detection. YOLOX is known for its fast, yet accurate performance, making it well-suited for object detection in panoramic photos.
One of the key advantages of YOLOX is its ability to achieve high accuracy while maintaining fast inference times (Faster than EfficientDet). This is achieved through a number of optimisations, such as anchor-free object detection, improved feature extraction, and more efficient use of memory. YOLOX processes feature maps at multiple scales to enable multi-scale detection.
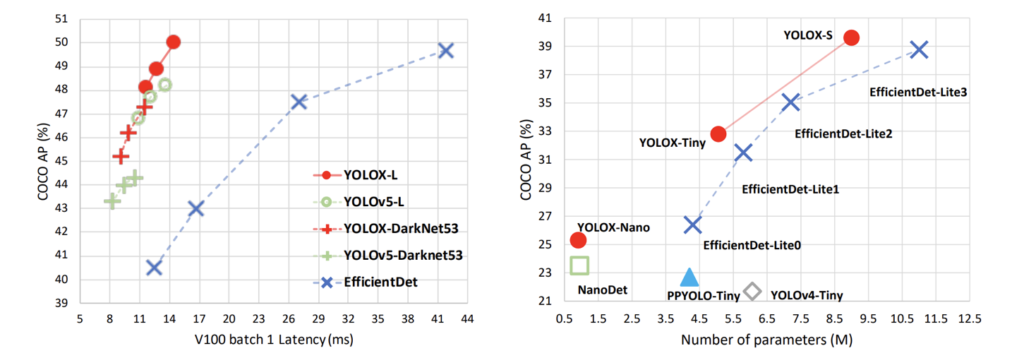
Overall, the YOLOX object detector is well-suited for use in panoramic photos and has been shown to achieve state-of-the-art performance on a variety of object detection computer vision tasks. YOLOX is one of several models for object detection, and there are various object detection methods in the field. Its speed and accuracy make it a popular choice for a variety of real-world applications, from autonomous vehicles to surveillance systems. YOLOX performs both object classification and object localization in a single pass. It can handle multiple classes and discretizes the output space for efficient detection.
SAHI framework for computer vision training
One approach to training object detection models for panoramic photos that has yielded great results for us is the Sliced Aided Hyper Inference (SAHI) framework. In our case, SAHI involved splitting the images into overlapping patches and training the object detection models on those patches. Once trained, the model is used to perform prediction on whole images using sliced inference.
The concept of sliced inference is central to the SAHI framework. Essentially, sliced inference involves performing object detection inference over smaller slices of the original panoramic image and then merging the sliced predictions to generate a complete object detection output for the original image. The process is illustrated below:

By breaking the panoramic image into smaller slices and training on those, the object detection model can more easily handle the challenges of large image size and small object size, which are common when working with panoramic photos. Additionally, the SAHI framework provides a mechanism for unifying the predictions generated by the model on the individual slices, resulting in a more accurate and comprehensive object detection output for the entire panoramic image.
Using SAHI is as easy as importing it and calling a single function by giving it our trained model specification and path to the data. The SAHI framework handles the rest, and the results are saved in a directory of our choosing. Sample code snippet presented below.
from sahi.predict import predict
predict(
model_type="mmdet",
model_path="path/to/model/file.pth",
model_config_path="path/to/model/config.py",
model_device="cuda:0",
model_confidence_threshold=0.25,
slice_height=512,
slice_width=512,
overlap_height_ratio=0.2,
overlap_width_ratio=0.2,
source="test-images",
project="test-images-predictions"
)An example prediction can be viewed below. Note that even very small traffic signs in the background are detected with high confidence.



Overall, the SAHI framework has proven to be an effective approach for training object detection models for panoramic photos, allowing for improved accuracy when compared to traditional object detection techniques.
SAHI alternatives
Some alternative approaches to detecting objects in large-scale images include:
- Image resizing: In this approach, the input image is resized to a smaller size before being processed by the object detection algorithm. This can reduce the algorithm’s computational complexity, but it can also result in lower accuracy, especially for small objects.
- Region-based approaches: In this approach, the image is first segmented into regions of interest, and the object detection algorithm is applied to each region individually. This can be an effective way to reduce the computational complexity of the algorithm, but it can also result in missed detections if the regions of interest are not properly defined.
- Specialised object detection architectures: Feature-Fused Single Shot Detectors (FFSSD), Multi-scale Deconvolutional Single Shot Detector (MDSSD) or QueryDet can be used, however, those approaches are not mainstream and usually require high investments in both researching the paper findings as well as recreating and re-training the network.
In our case, we did not want to compromise between the model’s accuracy and the implementation difficulty, so we opted for using SAHI for our purposes.
SAHI limitations for object detection models
While the SAHI framework has proven to be an effective approach for training object detection models for panoramic photos, it does come with some limitations. One of the main challenges of using SAHI is the increased inference time and compute power required due to the need to handle multiple image patches and merge the resulting predictions.
Several possible strategies can be employed to mitigate the increased inference speed and compute power requirements of SAHI. One approach is to limit the portion of the image that is processed by the object detection model.
For instance, removing the bottom and top 25% of the image reduces the number of patches necessary to generate good predictions. Removing those portions of the image in our case is justified, since the top and bottom of the panorama image usually contain the sky and the road surface, respectively. The most distortions, due to the fish-eye effect also occur in those regions. By including patches from those regions, we only waste computation, as the model cannot detect road furniture effectively – resulting in a larger number of false positives.
Another strategy is to optimise the SAHI framework to improve its efficiency. This can involve optimising the object detection model itself, as well as the post-processing steps that are used to stitch together the predictions generated by the model on the individual image patches (current SAHI implementation uses sequential patch processing instead of batching).
Additionally, advancements in hardware, such as the use of specialised processing units like GPUs or TPUs, can also help boost the inference speed and reduce the computing power requirements of SAHI-based object detection models.
Overall, while SAHI can be a powerful approach for training object detection models for panoramic photos, it is important to consider the potential limitations of this framework, and to explore strategies for mitigating these limitations to achieve optimal performance.

Examples of using very small object detectors and large images
Despite the challenges of working with panoramic photos or detecting very small objects, there are several examples of how object detection models can be used to provide real-world benefits.
Autonomous vehicles
Object detection models can be used in autonomous vehicles to identify objects within the environment, such as pedestrians, cars, traffic signs, and other infrastructure features. In city environments, panorama photos provide a wealth of information about the surroundings, making them an excellent data source for systems that detect different objects on the road.
Security systems
Security systems can use object detection models to identify potential threats within a city. For example, CCTV cameras placed in public spaces can use such methods for person detection and identifying suspicious behaviour, such as someone carrying a weapon or acting erratically.
Geospatial
Geospatial applications, such as object detection from satellite imagery, can also benefit from using very small object detectors. In fact, detecting and classifying small objects in satellite imagery is critical for many applications in areas such as environmental monitoring, agriculture, and national security.
Object detection models can be used in environmental monitoring to identify changes in the environment, such as deforestation or pollution. Large-scale images can provide a comprehensive view of the environment, making them an excellent data source for a state-of-the-art detection system.
Medical imaging and microscopy
In medical imaging, the detection of small objects is essential for recognising and diagnosing diseases like cancer. For example, detecting tiny tumours or lesions in MRI or CT scans can be critical for early diagnosis and treatment. In microscopy, small object detection is used to detect and analyse the structure and behaviour of microscopic organisms and cells. This can include detecting specific proteins, cellular structures, or pathogens.
Object detection in large panorama images: conclusion
Building object detection computer vision models for panorama photos of cities using the SAHI framework is an exciting area of research with many potential applications. The SAHI framework allows for accurate and efficient object detection in images, making it an ideal choice for developing computer vision models for panorama photos. With the increasing availability of panoramic photos from platforms like Google Maps, the potential applications of object detection models for city panorama photos are endless.
If you’d like to use state-of-the-art object detection models in your product, visit our Artificial Intelligence and Machine Learning offering page and contact us for more information.
Additional resources: SAHI framework
Object detection in large panoramic images involves identifying and locating objects within extremely high-resolution photographs with a wide field of view. As these images are much larger than standard pictures, special processing techniques are required to analyse them effectively.
The main challenges are their enormous size, which requires significant computing power, and the difficulty of maintaining accuracy when detecting small objects within large, detailed scenes.
Image tiling involves dividing a large panorama into smaller, more manageable sections. Each section is processed individually for object detection, which makes it easier to handle high resolutions and improves detection performance.
Common tools include deep learning frameworks such as TensorFlow and PyTorch, as well as object detection models such as YOLO and Faster R-CNN. These are often combined with custom preprocessing pipelines for handling large images.
Industries such as security surveillance, traffic monitoring, environmental research and industrial inspection can all benefit greatly from panoramic images, which allow wide areas to be monitored and objects to be analysed in detail.




Leverage AI to gain competitive advantage. Contact our expert to discuss your needs.

Tomasz Smolarczyk
Director of Artificial Intelligence
arrow_circle_right Our blog




