Automate data labelling with transfer learning
To support autonomous driving analysis, we built computer vision models that automate the labelling of road recordings. The solution detects and classifies traffic signs, reducing manual work from days to minutes and enabling teams to process significantly more data.

Services
Business need
One of our clients was building an analysis tool related to autonomous driving. With a new project on its way, they were faced with the task of analysing the content of road recordings. This task required the manual work of many people who analysed the route and marked many different objects visible on it.
Such a problem is very common nowadays. The development of computer vision methods allows for solving multiple business problems at once. However, in order to train the appropriate models, we must have properly labelled data. Usually, we need big amounts of data to train a Deep Learning model, which is associated with a high workload for manual labellers.
Our team’s task was to create ML models that would allow for a partial automation of the labelling process. We decided to start off with labelling road signs.
Computer vision
While we can easily grasp the machines’ ability to analyse a large amount of structured data such as tables from credit scoring, the fact that the machine can recognise and understand an image or a video is something much more counterintuitive and impressive.
With recent developments in computing power, newer and better machine learning methods, we already well into the territory often associated with Sci-Fi books and movies. Self-driving cars, face recognition available in a device we all carry in our pockets, machines deciding if there is a spot visible in x-rays of our lungs, or whether the skin condition we’ve just taken a picture of is potentially dangerous. Those are all well researched and working applications of Computer Vision.
Most of them can be divided into a couple of main categories:
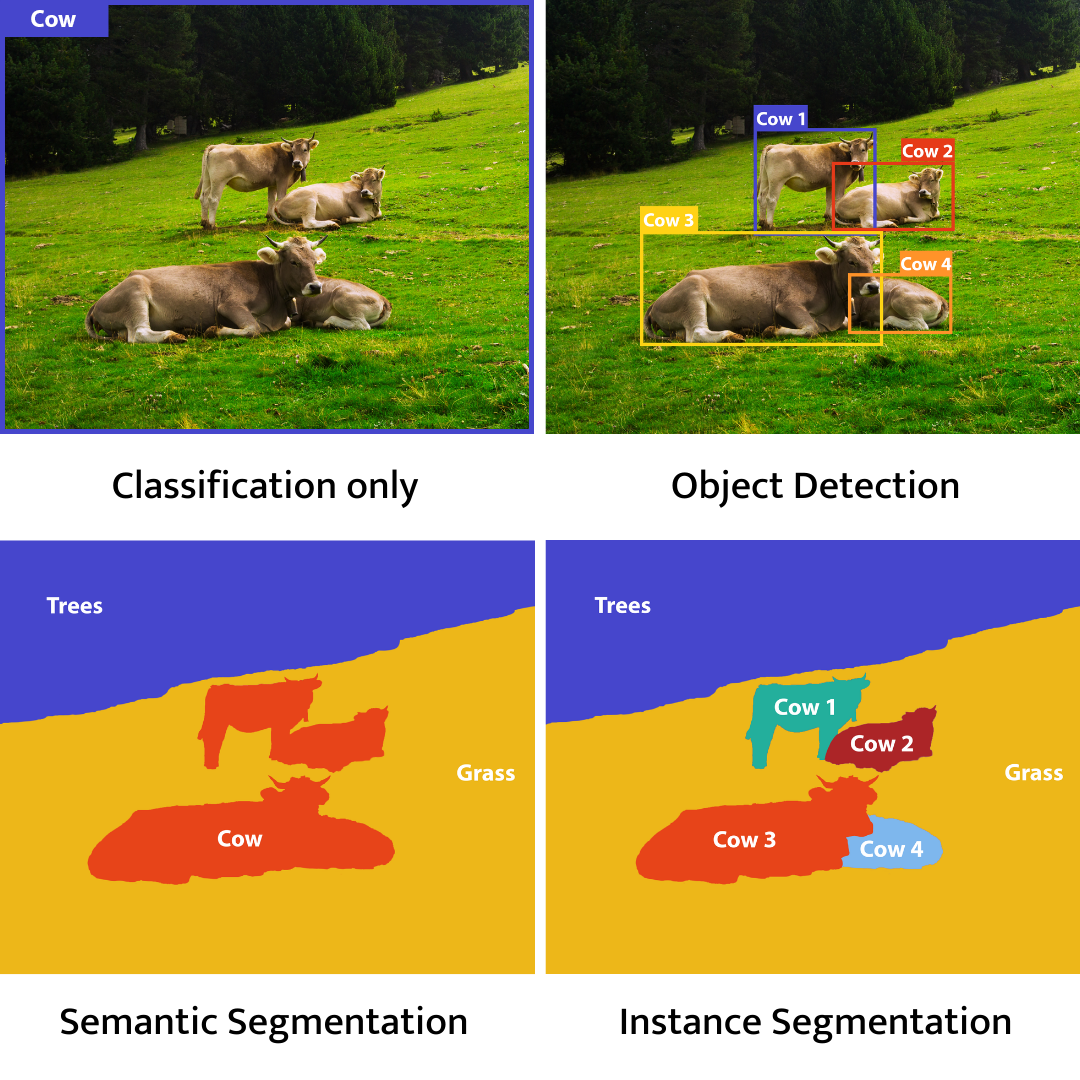
Image Classification – Deep Learning algorithms task is to classify an image or a video into one (or many) classes. With this kind of model, we can, for example, decide if the skin lesion is malignant or not (in this case, a picture is assigned to one of the two classes – malignant, non-malignant).
Object Detection – used to detect objects visible on the image. With this technique we can, for example, detect humans in the video recording or count blood cells in microscope images.
Segmentation – focused on partitioning an image into segments. Each pixel is classified and grouped accordingly. We use those methods mostly to locate boundaries in images.
- Semantic segmentation – We assign a class to each pixel, and we do not recognise separate instances of objects. For example, if we see multiple buildings, they will all be labelled as “building” and there will be no information on which one is it.
- Instance segmentation – Contrary to semantic segmentation, we consider instances of objects. We also classify each pixel but in this case we also take notice of separate objects. In this example, we will number the buildings visible on the picture as building #1, building #2, etc.
Object tracking – Using both detection and classification, we are also able to track a given object. If in the video we see a car driving through the street, we are able to track the movement with the information that this is the same car, not another instance of a new object.

Solution description
We considered various approaches during the experimental phase of the project.
Ultimately, we decided to create two separate specialised models and leverage the transfer learning principle.
In the case of Computer Vision tasks, transfer learning usually means using previously trained neural networks as the basis. The base network was trained on massive datasets and was able to learn to recognise generic shapes and patterns. Using such a network, we can then further retrain it to address our specific need.
Let us present this idea in a more illustrative way on our specific use case. The neural network used as the backbone was previously trained on a substantial number of images and taught to recognise basic, everyday objects, such as cars, trees and fruit. We use a part of this network to solve our problem.
That part might be able to recognise shapes, colours and various other patterns very well. By using a smaller number of photos of marked road signs, we are eventually able to additionally train such a network to recognise road signs. We have partially bypassed the learning process, during which the network acquires knowledge about the basic attributes of the image. Thanks to that, we do not need such a large amount of training data.
In our solution, the first model is focused on object detection – finding all road signs visible in the frames taken from the recording.
After being recognised, the images of the signs are later exported and saved. These images are then transferred to the second model with a single task of classifying the sign, that is to give it an appropriate meaning and context.
Combined in one pipeline, both models will be able to recognise and classify road signs in the entire recording in a matter of seconds. Thanks to that, the work performed by the labellers can be transferred to the analysis of the model predictions and possible corrections. This way, we can analyse many more recordings at the same time. An additional advantage is a faster delivery of new data points (labelled images), which can then be used to re-train the models and improve their effectiveness.
Results of collaboration
At the beginning, our client used video recordings of a road and its surroundings to manually label traffic signs visible from a vehicle’s perspective. Manual labelling required days of diligent work of 4 employees. Only after the annotation was done, they could cross-check their labels and confirm the final labels.
Thanks to our solution, instead of days of work, we label the recording in a matter of minutes, and only one person is needed to verify the results of the model. This allows us to shift the workforce to confirming the predictions, which means that we can process higher number of recordings at the same time.

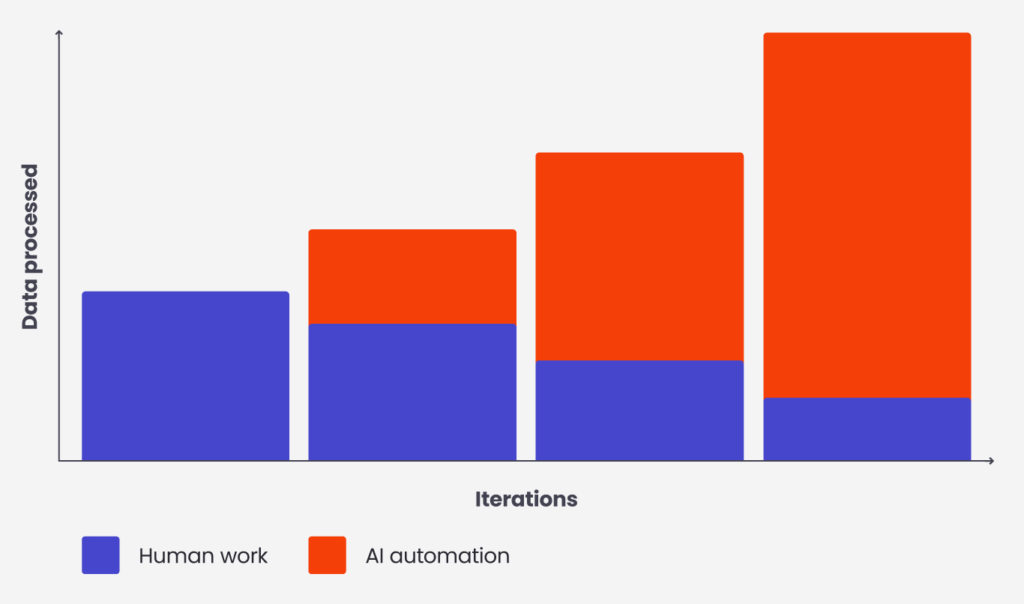
Similar solutions can be used for many tasks related to the recognition or classification of the selected patterns or objects in images.
If in a given industry, we encounter images that can provide us information – we can find an application for similar AI algorithms.
In addition, such tasks are increasingly supported with cloud solutions. A data practitioner with appropriate skills can relatively quickly create the necessary models and implement a Proof of Concept.
arrow_circle_right Case Studies
Read the success stories of our clients


arrow_circle_rightCONTACT
Let’s plan how AI can benefit your business

Tomasz Smolarczyk
Director of Artificial Intelligence