‘Can you enhance that?’ – part 1: Introduction to super resolution

What is super-resolution?
Super-resolution imaging (SR) is a class of techniques that enhance (increase) the resolution of an image from low-resolution (LR) to high-resolution (HR). In recent times Deep learning (DL) techniques have been fairly successful in solving the problem of image and video super-resolution.
In this article you’ll find SR usage scenarios, the theory behind them, various techniques used, metrics and the “before” and “after” visualisation examples.
Usage scenarios
Surveillance

source: https://www1.nyc.gov/site/nypd/services/see-say-something/crimestoppers.page
SR can be used to detect, identify, and perform facial recognition on low-resolution images obtained from security cameras. Application of the SR techniques to enhance surveillance footage is the closest thing to what we can see in the CSI TV Series.
Medical Imagery
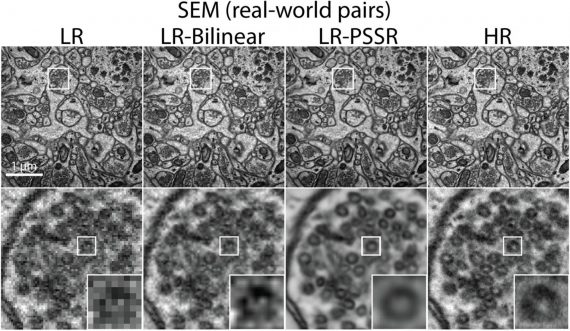
Capturing high-resolution MRI images can be tricky when it comes to scan time, spatial coverage, and signal-to-noise ratio (SNR). Super resolution helps resolve this by generating high-resolution MRI from otherwise low-resolution MRI images.
Satellite imagery

The other instance when you might want to apply SR to your images first is when the HR data collection is expensive. This is especially true for satellite imagery, where 1 sq. km of 30cm imagery can cost over $25. The cost of imagery with resolution of 1m is around $10 per sq. km. This means that, for a batch of 1000 sq. km you pay $10,000 and not $25,000 – this means huge cost savings for your company.
Media
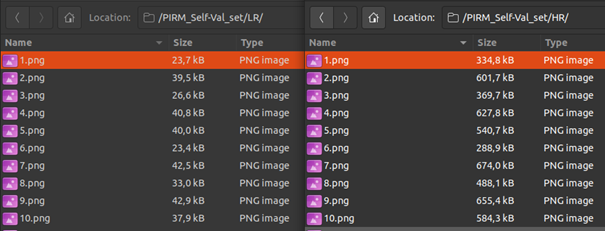
Super resolution can be used to reduce server costs as media can be sent at a lower resolution and upscaled on the fly. Figure above presents difference between LR and HR PIRM self-val images (https://pirm.github.io/). On the left we have 4x downscaled images, and on the right the original HR images.
Real-World Super Resolution

SR can be used to reduce artifacts and noise from real-world images. Basically, you can enhance all of your selfies and vacation pictures before uploading them to Facebook or Instagram.
Game optimisation – DLSS

DLSS (an acronym for Deep Learning Super Sampling) is a deep learning neural network that uses the power of the NVIDIA RTX TensorCores to boost frame rates and generate sharp frames that approach or exceed native rendering. By tapping into a deep learning neural network, DLSS is able to combine anti-aliasing, feature enhancement, image sharpening and display scaling which traditional anti-aliasing solutions cannot. With this approach, DLSS delivers up to 2X greater performance with comparable image quality to full resolution native rendering. It gives you the performance headroom to maximize ray tracing settings and increase output resolution. DLSS is powered by dedicated AI processors on RTX GPUs called Tensor Cores.
In conjunction with other DL techniques
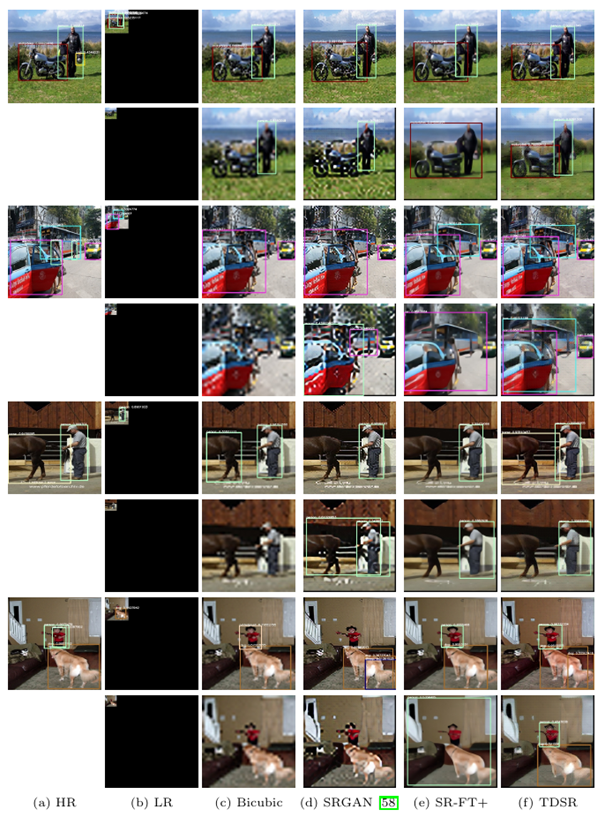
Imagine that you have a bunch of data and want to do some object detection with it. However, the data is really low quality, perhaps from old or cheap video cameras. And when you try to apply your plain DL models, they don’t perform too well… You can boost their performance by first running your images through SR network.
In the next article in this series, I’ll tell you more about digital image resampling methods and how to measure their performance.
About the author
Michal Wierzbinski
Lead AI Data Scientist
