JSONB in JAVA projects


Backend programmers have been able to store data in JSON format for a long time, since PostgresSQL 9.2. This solution has a number of advantages. Unfortunately, it has also several disadvantages.
Since version 9.4, the binary representation of JSON – JSONB – has been introduced, which saves data a bit slower than JSON, but speeds up its processing and gives the ability to create indexes. It’s common knowledge that you can do indexes on a JSONB column, but the topic is quite complicated and you can end up with inefficient queries.
In this article, we’ll focus on JSONB. I’ll present good practices for using this type of column and emphasise its limitations.
Example of how to create a table and fill it with data
I like to visualise what’s being said, so let’s create a table with JSONB type column with some data:

JSONB type column contains a text field (name), a list (waterfalls), and a map (attractions).
After executing “select * from holidays” we will get:
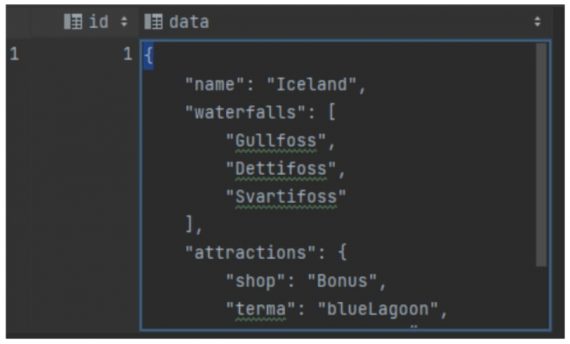
Creating such a model is simple. There’s no need to specify field types. Everything was converted to JSONB without any problems. The ID column was added because the table will map to an entity in JPA that requires an ID.
The application of JSONB
When to use JSONB:
- Unpredictable data structure: we have to keep data in the database, but it is not clear what data we will get from an external supplier. Or we allow the client to define their own fields.
- A lot of attributes (fields) that are rarely used, e.g. data that is kept in the database only for displaying. Or we keep them just because one day they may be useful.
- Relationship to multiple objects: when we do not want to apply the JOIN clause to a table with relationships for performance reasons. We can easily save the list of relations in JSONB.
When not to use JSONB:
- Inefficient queries: Postgres in queries uses statistics that are not kept for JSONB. It guesses how to execute a query and sometimes makes a wrong guess. Thanks to indexes, you can speed up the query, but I will write more about it later in the article.
- Limited disk space: KEY and VALUE are kept in JSONB. If you have a million records and you hold KEY/VALUE for each of those records, the KEY will be duplicated a million times. I suggest you read the article that describes how the disk space was reduced by 30% after removing 45 keys to the columns – https://heap.io/blog/when-to-avoid-jsonb-in-a-postgresql-schema
- When we want to make a constraint on a field: it is not easy to make a field unique.
Optimisation of queries: a closer look at indexing

B-Tree: It only works with the equality (=) operator. It can be done for the entire JSONB column or as a function on a specific field.
Hash: Similarly to a B-tree, it only works with the equality (=) operator. It can also be used on a field in JSONB. With B-tree, queries are faster than hashs, but take up more space and the inserts take longer.
Gin:
- Postgres has built-in operator classes for the GIN index (https://www.postgresql.org/docs/current/gin-builtin-opclasses.html)
GIN Index with the JSONB_OPS class operator (default) supports existence operators (?,? &,? |) and containment (@>). It only works on KEY. It can be done on a column or a field. You have to watch out for disk space, because it takes a lot of space. It’s less effective than Hash and B-Tree, but more flexible.
- Gin with JSONB_PATH_OPS class operator only supports @> but takes less space, SELECT, UPDATE, DELETE and build time is faster than JSONB_OPS.
- Gin with the use of GIN_TRGM_OPS as the only index supports the like operator. For this, you need to install the PG_TRGM extension. It only works for values, not for keys.
What does Java queries look like?
In my projects, I use various methods of making queries using Spring Data JPA. In order to try to use the created indexes on the JSONB table, we will focus on 3 options:
- @Query declaration
- Specifications
- @Query declaration with native query
@Query declaration
JPA doesn’t support JSONB operators (- >>? @> Etc). For example, the operator – >> can be replaced with the JSONB_EXTRACT_PATH_TEXT function.
![]()
A similar query can be obtained using the specification.
Specifications
![]()
Using specifications for queries is not readable, but it’s great for building dynamic queries. Unfortunately, writing a query using a function will not be efficient. If we create an index: BTREE ((data – >> ‘name’)), it will be omitted when executing the query using specifications. If we want to speed up the query, we can use the CREATE INDEX function index func_hname_indx ON holidays (jsonb_extract_path_text (data, ‘name’));
@Query with a native query

Native queries make it possible to use operators intended for JSONB searches, e.g. data – >> ‘waterfalls’ and thus, the use of indexes.
In the following section, I will describe a list of queries with performance information.
The examples of creating indexes and queries
* SEQ = Sequential search across the entire table
* Index scan = quick search using the index
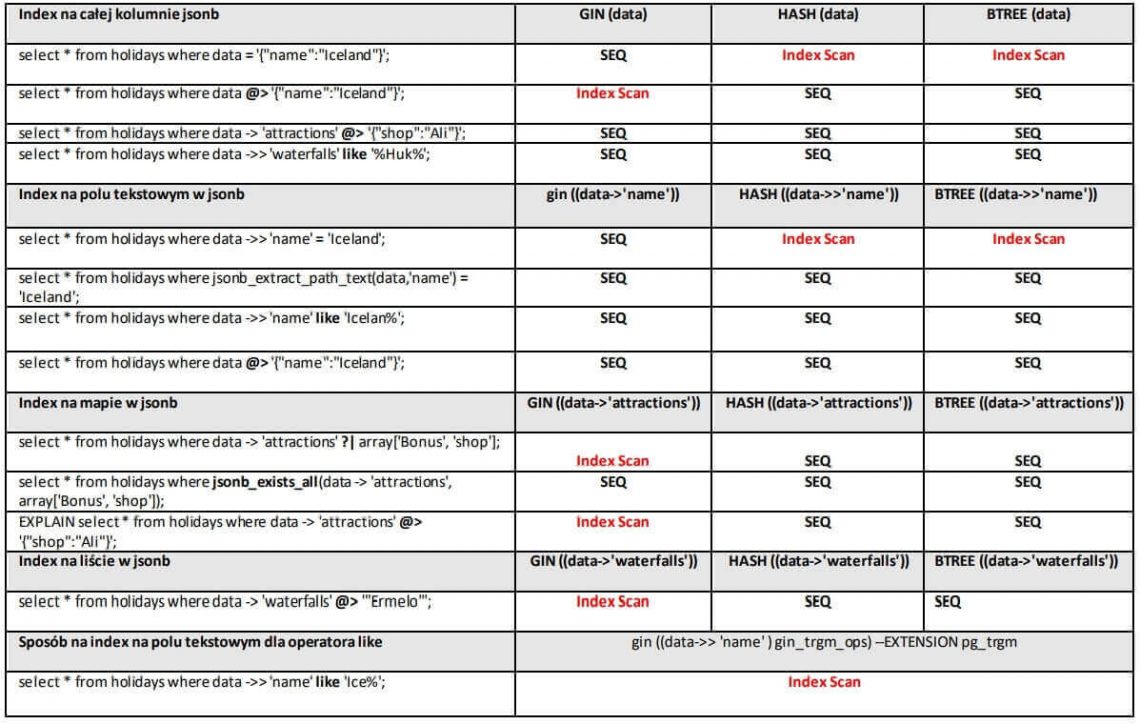
The above list shows the flexibility of the Gin index, which can be used in many situations.
For people who avoid native queries in the code, but need an index, I want to show an example of a function index that can be used and implemented with @Query.

Sorting the results: the “order by” clause is only supportedby the BTreeindex

Summary
JSONB is very useful in many cases, especially for read-only data and data that do not require advanced queries.
If our project requires the use of JSONB and more complex queries, we can always create an index and implement a native query.
For large databases (more than 1 million records), you need to be extra careful and consider keeping the data in the traditional columns for which the statistics are kept and used for query optimisation.




arrow_circle_rightContact us
We’ll help you choose the best fitting technology for your solution

Marcin Zyga
Chief AI & Information Officer
arrow_circle_right Our articles





