Choosing the best time-series database for your IoT needs – a comparison


Time-series data lies at the core of many IoT applications. Devices generate readings in near real-time, producing large volumes of timestamped data that must be stored efficiently, ingested quickly, and retrieved easily for analysis. While traditional relational databases can store time-series data, they are not always optimised for the unique access patterns required – such as time-based aggregations or rapid ingestion with minimal delays. So, in this article, I will focus on choosing the best time-series database for specific needs.
Below, I’ll compare four popular solutions for time-series storage and analytics:
- TimescaleDB – An extension on top of PostgreSQL, providing time-series optimisations while retaining the familiarity of SQL.
- InfluxDB (v3) – A purpose-built time-series database known for high-throughput ingestion and a rich ecosystem.
- Azure Data Explorer (ADX) – A fast, cloud-native analytics service from Microsoft Azure, optimised for log and telemetry data.
- AWS Timestream – A fully managed time-series database service by AWS, designed to scale with minimal operational overhead.
Although TimescaleDB and InfluxDB also have cloud-based offerings, for the purpose of this article, I will focus on their availability as on-premises time-series solutions.
At Spyrosoft, we always consider these options at the beginning of a new IoT project, based on the specific requirements. The goal of this article is to compare these solutions for IoT data storage and analytics. To be clear, there is no single “golden rule” or universal best choice when selecting a time-series database. However, I will present the key considerations you should keep in mind when choosing a time-series solution, by providing a comparative overview.
Let’s get started!
Data organisation in time-series database
Efficient data organisation is essential to the performance and optimisation of the best time-series databases. Solutions like InfluxDB, TimescaleDB, Amazon Timestream, and Azure Data Explorer can each employ distinct schemes to structure and store time-series data effectively.
InfluxDB Clustered
InfluxDB allows you to store data in a named location called a database (referred to as buckets in InfluxDB TSM), which groups data logically into tables (known as measurements in InfluxDB TSM). Each table contains tags and fields:
- Tags are key-value pairs that provide metadata for each point – examples include identifiers like station, sensor ID, or location. Tag values may be null.
- Fields are key-value pairs representing values that change over time – examples include temperature or pressure. Field values may be null, but at least one field value must be non-null in any given row.
A timestamp (which is never null) is associated with each data point, and all data is ordered by time. The term “point” refers to a single data record identified by its measurement, tag keys, tag values, field key, and timestamp. All points in a given table should share the same tags. The columns that uniquely identify each row in a table form the primary key. Rows are uniquely identified by their timestamp and set of non-null tags.
When you write data to InfluxDB, the data itself defines the schema. There is no need to explicitly create tables or define a schema in advance.
TimescaleDB
TimescaleDB is built on PostgreSQL and distributed as a PostgreSQL extension, maintaining full SQL support. The solution organises time-series data in hypertables, which are essentially PostgreSQL tables partitioned by time. The database automatically manages these partitions behind the scenes. A hypertable consists of smaller tables called chunks, each assigned a time range to store only data from that interval. The chunk size configures itself during the hypertable creation, so it should be carefully planned, as it affects insert and query performance. By default, a newly created hypertable indexes by time in descending order. Hypertables can coexist with standard PostgreSQL tables, which can be advantageous in certain scenarios.
Timestream
Amazon Timestream stores data in databases that contain tables, similar to InfluxDB’s structure. Each table holds a time series, which is a sequence of one or more data points (records) captured over a time interval. A single data point in the time series is called a record.
An attribute describing the metadata of a time series is known as a dimension, and it consists of a name and value (for example, “device_id” and “12345”). A measure is a value tracked by the record, identified by a measure name and measure value (for example, “temperature” and “45”). A timestamp indicates when the measure was collected, with nanosecond granularity.
Azure Data Explorer
The top-level container in Azure Data Explorer is a database, which holds tables. Each table stores data in extents (data shards). An extent is a table’s horizontal segment containing data and metadata, such as its creation time and optional tags. All extents together form the table. They are also evenly distributed across cluster nodes and cached in both local SSDs and memory for optimal performance. Essentially, they are immutable, and each extent physically stores records in columns.
Querying data with top time-series databases
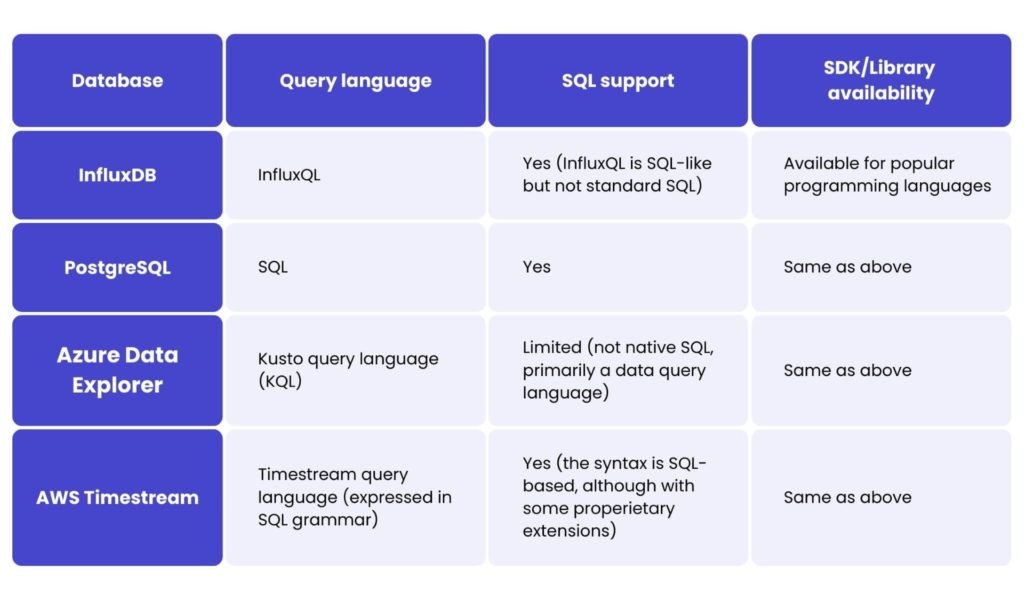
Ingestion methods for time-series databases
Ingestion strategies vary widely across these time-series databases, reflecting the diverse needs of IoT applications.
- InfluxDB supports high-throughput writes through its line protocol via HTTP, as well as integrations with tools like Telegraf (a server-based agent that can collect and send metrics and events from IoT sensors) for streaming and batch imports.
- TimescaleDB, being a PostgreSQL extension, leverages standard SQL inserts, bulk timescaledb-parallel-copy operations for importing data, e.g., from CSV files, and external connectors.
- AWS Timestream provides native integrations with AWS IoT core and Kinesis data streams, while also offering an SDK-driven approach.
- Azure Data Explorer (ADX) can ingest data from Event Hubs, IoT Hub, or direct HTTP-based endpoints, automatically batching and managing data shards.
Best time-series database: Hosting options
Each of these time-series databases offers different hosting options, which can influence cost, scalability, and operational complexity.
InfluxDB
There are many ways to implement InfluxDB into IoT solutions: as a self-hosted on-premises instance, in a private cloud, or using InfluxDB Cloud, a fully managed SaaS offering. The self-hosted version provides complete control over infrastructure but requires operational management. For this article, we focus on InfluxDB hosted on-premises. You can deploy a single instance of InfluxDB, or utilise InfluxDB Clustered, designed with high availability and scalability in mind. Deploying InfluxDB Clustered on Kubernetes requires additional resources, such as persistent storage for underlying Parquet files that must be compatible with AWS S3 or S3-compatible object storage, and an external PostgreSQL (or PostgreSQL compatible) instance for metadata and coordination. It is also advisable to use a load balancer to efficiently distribute queries and ingestion requests across cluster nodes.
TimescaleDB
TimescaleDB is available as a self-managed PostgreSQL extension, making it deployable on any infrastructure where PostgreSQL runs. Additionally, TimescaleDB offers Timescale cloud, a managed service for hosting and scaling time-series databases with minimal operational overhead.
AWS Timestream
AWS Timestream is a fully managed, cloud-native service that is exclusively available within the AWS ecosystem. It eliminates the need for infrastructure management but requires AWS integration and follows a cloud-based pricing model. At the time of writing this article, AWS Timestream employs a pay-as-you-go pricing structure, with costs determined by data ingestion, storage, and query processing. For the most up-to-date pricing details, you should refer to the official AWS Timestream pricing page. Pricing should be assessed based on specific project requirements, as costs may vary depending on usage patterns and data retention needs.
Azure Data Explorer
ADX is a cloud-native service that runs on Microsoft Azure, offering a managed environment with built-in scalability. While it is optimised for Azure workloads, it can also integrate with hybrid and multi-cloud architectures through various ingestion methods. Azure Data Explorer provides multiple service tiers, including a Dev/Test cluster, which is designed for development and testing with a single node and no redundancy, and a Production cluster, which includes at least two nodes for high availability and operates under an Azure Data Explorer SLA. You should select an appropriate tier based on your workload requirements and cost considerations.
The one best time-series database is… or is it?
Well, it depends! There is no single perfect choice that fits all use cases. However, here’s a rough guideline for when each database might be the best option:
- If you need on-premises hosting – consider InfluxDB or TimescaleDB.
- If your team is already familiar with SQL and prefers PostgreSQL – TimescaleDB might be your best fit.
- If you require a fully managed, cloud-native solution on AWS – AWS Timestream is a natural choice.
- If your infrastructure is Azure-based and you need seamless integration with other Azure resources, such as Data Lake and Power BI – Azure Data Explorer is worth considering.
- If high ingestion rates and real-time analytics are critical – InfluxDB or Azure Data Explorer might be your best option.
Of course, these are just starting points, and the best approach is always to conduct a proof of concept (PoC) and load tests tailored to your specific project. After all, picking a database is a bit like picking a favourite pizza topping – what works for one team may not be the best for another.
Discover how we can elevate your IoT solutions
Learn more
Conclusions on selecting the best time-series database
There is no single “golden rule” for choosing the best time-series database for an IoT project. Each presented solution has its strengths and trade-offs, and the best option depends on the project’s specific requirements, such as scalability, ease of querying, and data acquisition performance. Nevertheless, you should definitely consider the factors outlined in this post when making a decision.
The good news is that deploying these databases is relatively straightforward, making it easy to conduct a proof of concept (PoC) that evaluates their performance in a real-world scenario. Once a PoC is in place, artificial load testing can help estimate how well a database handles expected workloads, ensuring the right choice before committing to a production system.
In my current project, we have followed this approach from the beginning. When we gathered telemetry requirements from the customer, we initially conducted a PoC with both Azure Data Explorer (ADX) and PostgreSQL. Given that the customer already had an existing Azure infrastructure and additional requirements – such as integration with other resources like Data Lake and Power BI – ADX emerged as the best fit for our scenario. It provided the necessary scalability almost immediately, with seamless integration into services like IoT Hub and Blob Storage.
Another important consideration was data migration from different sources. The ability to include external tables – such as sources stored in CSV files within Blob Storage – was also a significant advantage for our project’s needs. However, this does not mean that Azure Data Explorer is the best choice for every project. It was simply the most suitable option for us, considering our specific requirements.
Of course, it wasn’t all smooth sailing from the start. We had to refine our ingestion approach, configure data aggregation, manage data latency, and carefully consider data retention and continuous export strategies. Additionally, cost efficiency was a bit tricky – pricing for ADX isn’t always straightforward and requires careful analysis. But handling ADX and making it work efficiently is probably a topic worthy of its own post (and maybe even a few deep sighs in the process).
Tap into the best time-series database with Spyrosoft
Choosing the best time-series database for your IoT project is no easy task, but hopefully, this comparison has given you some valuable insights to guide your decision. Whether you’re looking for seamless cloud integration, SQL familiarity, or high-throughput ingestion, each database has something unique to offer.
If you need more IoT expertise or hands-on support in developing your IoT project, contact us via the form below, and see what we can accomplish together.
FAQ
A time-series database is designed to store data points collected over time, often at high frequency. Unlike relational databases, which focus on structured, relational datasets, time-series systems optimise for fast ingestion, efficient compression, and smooth querying of sequential data. This makes them much better suited for IoT scenarios where devices generate continuous streams of measurements.
Focus on ingestion speed, storage efficiency, query performance, and how well the database scales as data volumes grow. It also helps to consider ease of integration with your existing infrastructure and whether the system supports features such as downsampling or retention policies. The best time-series database for your project will match both your current load and your future growth.
IoT environments rarely stay static. Device numbers increase, sampling frequencies change, and new use cases appear. A database that scales without disruption allows you to maintain consistent performance and predictable costs as your environment expands. Without this, even well-designed systems can become slow or unstable.
Many open-source solutions provide strong foundations, large communities, and stable features. Their transparency also makes them easy to audit and customise. However, industrial projects may need additional safeguards, such as defined SLAs, enterprise support, or certified integrations. It often comes down to your internal capabilities and long-term maintenance plans.
Data retention policies determine how long you keep raw and processed data. A suitable policy helps you control storage costs without losing valuable insights. Some databases automate retention and downsampling, which is useful when handling long-term trends without storing unnecessary detail.
Slow queries can reduce the value of real-time monitoring. A database built for time-series workloads will handle aggregations, filtering, and window functions more smoothly. This gives engineers faster access to insights, supports alerting, and helps detect anomalies before they become costly issues.
Yes. Many organisations use a hybrid approach. For example, a time-series database might store high-frequency sensor data, while a relational or document database manages metadata, reports, or business logic. The important part is to design data flows that remain stable and clear as the system evolves.
You can rely on vendor resources, community documentation, or external consultancy. According to Spyrosoft, organisations benefit from having a partner who understands both the technical landscape and the practical demands of large-scale IoT platforms. Guidance of this kind can help you choose a solution that fits your long-term strategy.




arrow_circle_rightcontact us
Let’s talk about your IoT development strategy

arrow_circle_right Other articles





