Introduction to software engineering

At Spyrosoft, we take big pride in our knowledge-sharing culture. Given the ever-growing demand for software engineers, a clear trend can be observed – more and more people are willing to start their careers in IT even without a formal technical education. Seeing this trend as inevitable and natural, we decided to contribute to the growing database of resources for new software engineering adepts.
This article is the first one in a series devoted to software engineering basics.
Software engineering introduction – definition and meaning
Let’s define software engineering first. The history of software engineering begins in the 1960s. Its definition is pretty simple: software engineering is an engineering discipline that deals with all aspects of software production. What does that mean? Let’s decipher it.
THE FIELD OF SOFTWARE ENGINEERING
Software engineering is usually associated with coding, which is only a part of the entire spectrum of activities it encompasses. Here is a more comprehensive list:
- Planning
- Analysis
- Development
- Implementation
- Programming
- Design
- Testing
- V&V (verification and validation)
Most software engineering practitioners treat development, implementation, and programming as one common area. One could argue they are not the same, but it would be a rather theoretical and highly abstruse debate. For convenience, let us encompass them all under the single term of development.
If we are talking about software engineering, it is only natural that we should define the term “software” as well. Wikipedia, citing ISO/IEC 2382:2015 standard, defines software as “a set of computer programs and associated documentation and data. This is in contrast to hardware, from which the system is built and which performs the work.”.
To a contemporary person, software is a natural thing. Everyone uses it daily. Things like mobile applications or various web systems are an indispensable part of our lives. When looking at the software industry, it is important to differentiate between two usual types of companies: product companies and service companies.
As the name indicates, product companies produce a piece of software – a software product. Usually, the product is sold to any customer who is able and willing to buy it. It is, by its nature, a generic system, not necessarily tailored to the customer’s needs. On the contrary, service companies, like Spyrosoft, provide fully customised, dedicated products for a given client. At first, a thorough analysis of the business needs is performed and based on that, the product is designed, developed, tested and deployed into production. Generic software products are also called COTS products – commercial off-the-shelf products. Windows operating system is a very good example of such a product. It is available for purchase to any interested entity in the same form. Spyrosoft doesn’t sell such products. We create bespoke software solutions, dedicated tools for a particular client which are unique to their demands and business context.
SOFTWARE LAYERS
Software is a broad term and it might be beneficial to stratify it into several layers. Some of these layers are not necessarily relevant to what we do at Spyrosoft, but it is good to have a thorough picture and understand the context of each layer. There are eight layers:
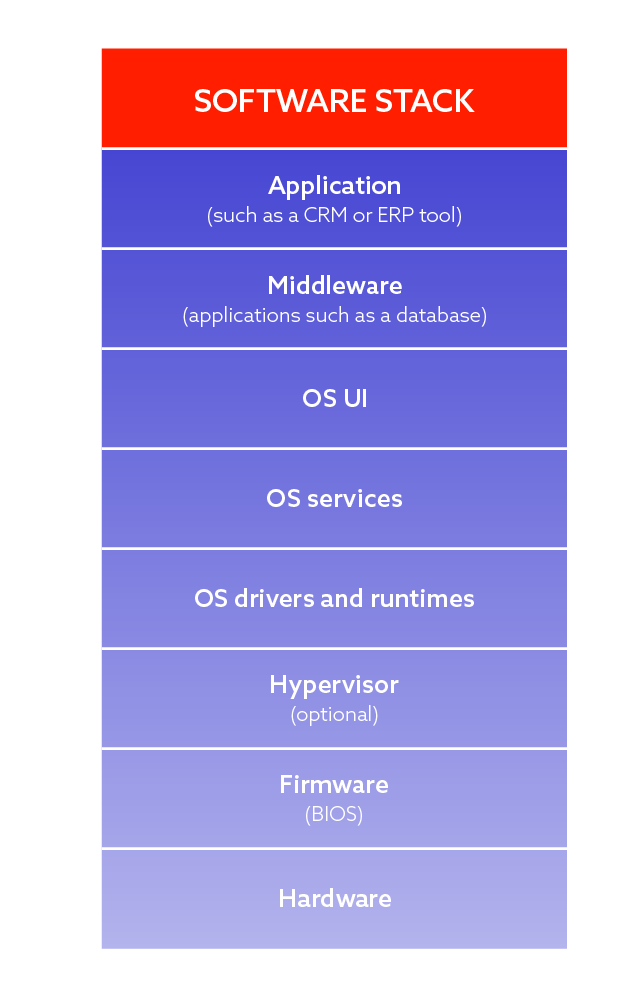
Hardware
The lowest layer is not actually software, however, each software runs on some kind of hardware, so it is included here for completeness. At Spyrosoft, we don’t provide hardware solutions, but in our embedded departments, we deal with low-level software highly dependent on the underlying hardware.
Firmware (BIOS)
The lowest layer of software which can be provided. Firmware is essentially software that controls the underlying hardware. The higher layers of software do not interact directly with the hardware but rely on the firmware to do that interaction. Thus, firmware provides an abstraction layer and, to some extent, makes higher-level software independent of the hardware.
Hypervisor
A hypervisor is an essential tool for managing the virtualisation processes – it is software that creates and runs virtual machines.
The operating system
It can be divided into runtime and drivers, services and finally user interface. Everyone knows operating systems, such as Windows, Linux or Android and their graphical user interfaces. We are used to high-level interactions, e.g. we click on an icon on our desktop and something happens. In reality, such a simple mouse click will usually trigger a lot of processing in various software pieces. Let’s imagine you want to send a message to your friend using one of the popular messaging apps. It seems to be really easy, doesn’t it? Just type in the message, press ENTER and wait for the reply. However, there’s much more going on behind the scenes. Let’s break it down a bit:
- First, you use the GUI (graphical user interface) of your operating system to type in the message into a window of the chosen application.
- There’s bound to be an operating system service responsible for network communication that actually prepares the message to be transmitted over the internet. It is also responsible for receiving incoming messages and translating them into a format digestible by higher-level applications.
- In the end, the message needs to be physically transmitted over a medium, e.g. a wire or wirelessly over-the-air. It is the job of the lowest software layers, like drivers, to make sure the hardware performs the actual data transmission.
Hopefully, this clearly presents that seemingly simple interactions may invoke a massive series of software events and activities and that operating systems are quite complex software systems.
Middleware
The middleware is also called “software glue”. It provides services to software applications beyond those available from the operating system level. Database access services are often characterised as middleware. To simplify things, you can think of middleware as applications without a graphical interface. Middleware is not a clickable tool. It works on the backend. You can communicate with it but not how you are most probably used to – a mouse and touchscreen won’t work in this case. Middleware responds to a message sent in a particular format over a defined communication channel, e.g. a TCP/IP port.
The application
The last software layer is the application layer. Applications are used on a daily basis by most of us. A perfect example of an application is a web browser. Other examples are MS Teams, Outlook, or Excel.
Fundamental software engineering activities
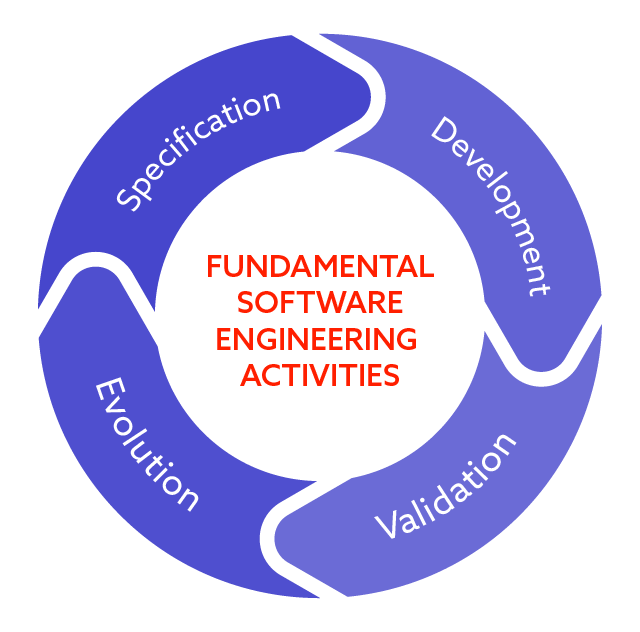
Knowing what software is, it is time to take a deeper look at various activities software engineers perform. This is just one of the models. Its simplicity will hopefully help you understand the software development process better.
- Specification
A software engineer needs a specification to start their work. Usually, specification is a kind of documentation that can help you understand what software is supposed to do.
- Development
Generally, if it is clear what software is supposed to do, the design and development phase can be started.
- Validation
At this stage, the actual software is verified against the corresponding specification.
- Evolution
Much software dies over time because businesses, markets, and thus the needs of companies and the expectations of software users change. Therefore, it is necessary to evolve the developed software regularly. It is a process that can last for many, many years (do you remember when the first version of Windows OS was published? In 1985 and it’s still there)
All the stages presented above form a cycle. If something changes, you must gather specifications again, take up development anew, and validate the developed software or the changes made, and thus, the software evolves.
Software engineering vs. computer science
It is also worth being aware of the differences between software engineering and computer science. They might appear similar, but they are, in fact, pretty different. Computer science focuses on theory and fundamentals; software engineering is concerned with the practicalities of developing and delivering useful software. That’s the difference. Software engineering is efficient and focused on providing working software.
In other words, companies/institutions (a huge part is done by academia) specialising in computer science do research and look for new algorithms, methods, and ways to optimise existing solutions and methods. Spyrosoft, as the development company, isn’t, strictly speaking, a computer science company. We produce working software.
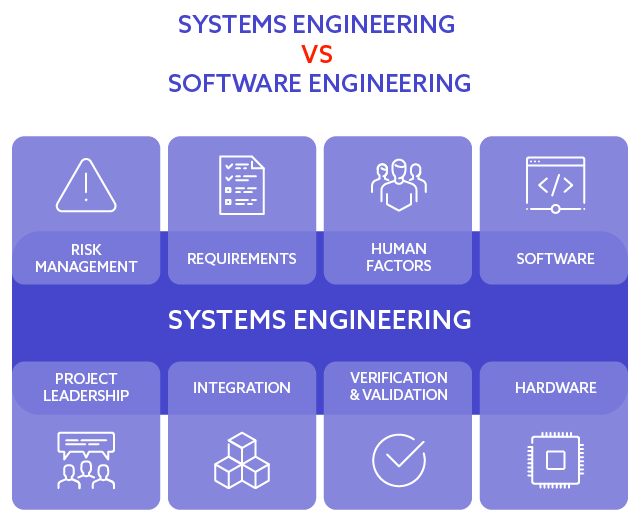
System engineering vs. software engineering
Software engineering not only focuses on software, but also on everyday life, as businesses do not revolve only around software. Factors like hardware, mechanical parts, materials, legal and compliance aspects, human decision-making, risk management and many others must be considered when running a business. That’s why a notion of system can be defined – a system, according to the Merriam-Webster dictionary, is a group of interacting or interrelated elements that act according to a set of rules to form a unified whole. Obviously, software might, and these days usually is, a part of a system. So, software engineering can be considered a part of systems engineering.
To illustrate the concept and delineate a boundary between software and non-software part of the system, we can look at two examples:
- A modern car and its ABS (anti-lock braking system): a simplified structure of such a system incorporates:
- Control unit – a piece of software running on specific hardware that can control the operation of the entire system.
- Wheel sensors – might require some software for operation but are, in general, hardware components.
- Hydraulic valves – mechanical components responsible for the actual braking.
It is clearly visible that the system is a lot more than just software. While software engineer only needs to focus on the control unit and make sure it is able to receive, process and then send signals to other parts of the system, systems engineer needs to focus on the entire operation of the system and design, and understand the interaction among all of its components. On the other hand, a systems engineer does not need to know all the intricacies of the control unit.
- A banking system for loan management
Being no bank expert, I can imagine that, for example:
- Loans for amounts higher than a defined limit, e.g. 1 000 000 PLN, need to be signed off by a regional manager – a human factor to be taken into account.
- For some legal or compliance reasons, specific documents might need to be printed off and stored in the archive – compliance activity to be incorporated into a system.
And again, it is clear that these are not software concerns but might be crucial for the entire business process and, therefore, system design.
At Spyrosoft, we focus on software design and development, but it cannot be done without the context of the entire system. We have a team of skilled systems engineers and business analysts that help our clients design their systems and map business processes to software.
Generic software system architecture
In order to understand how software systems work nowadays, it is beneficial to take a glimpse at the typical architectures of modern software systems. This time let’s not dwell on formal definitions but focus on the practicalities instead.
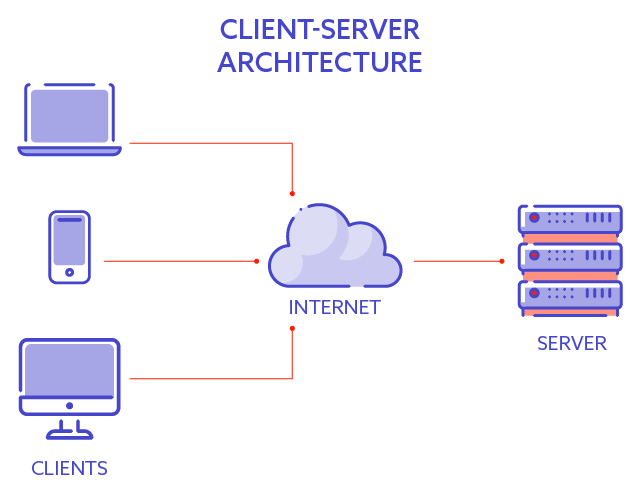
The most straightforward system architecture of a modern software system is a client-server architecture. There are two essential elements:
- The client – not the person using the computer, but an application running on that computer
- The server – not the physical server, but the application running on the server that is able to process the requests coming from the client.
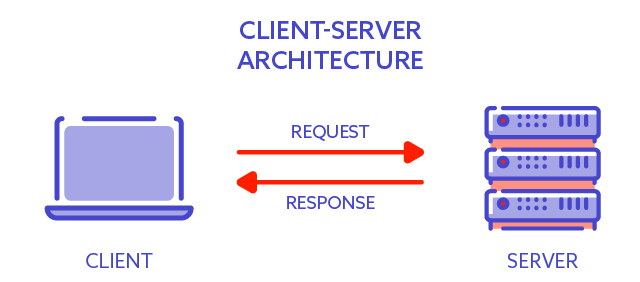
Let’s illustrate it with a real-life example, such as a banking system. When a bank client – the user of our system wants to transfer money, they open up the bank webpage and log into the system. Afterwards, using the controls on the webpage, the user can provide all the necessary inputs for a transfer. Such a request is sent over to the banking server, which performs the transfer. The server sends back the response to notify the user whether the operation has been successful.
So the client, in this case, is the web browser on the laptop or desktop computer of the user. The server is the application running on the server owned or leased by the bank. The user doesn’t need to know the server’s physical location as long as they know the address of the banking system (URL – uniform resource locator). The web browser knows where to send the request based on the URL, and then the server returns the results. In this example, the server is usually placed in a secure server room.
Obviously, users do not always carry around their laptops these days. A smartphone or tablet usually comes in more handy. A client in the example above might also be a banking application running on a mobile device. The device the user is using should not matter as long as the application can communicate with the server.
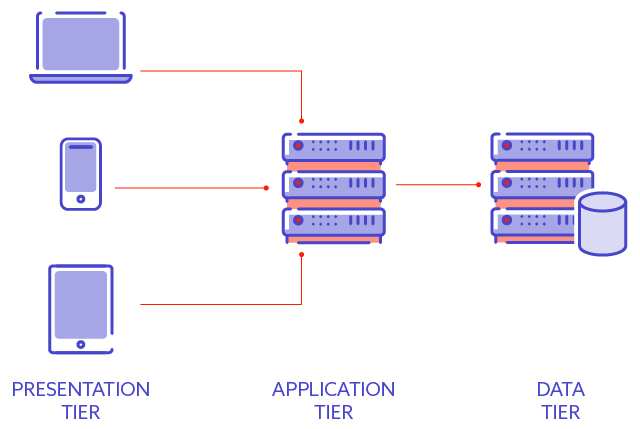
Three-tier architecture
If everything seemed very simple to you up to this point, let us further complicate the issue. The system design is relatively straightforward when limited only to the client and server. However, you can introduce another component, and instead of two tiers, there will be three tiers – thus, we get a three-tier architecture.
The additional tier, not present in the previous example, is the data tier. You can easily imagine that most companies deal with tons of data these days, so having a dedicated part of the system responsible for data processing and storage is a reasonable decision.
So the three tiers can be briefly described as follows:
- Presentation tier – user-facing part of the system, which lets a user, for example, input the data and receive communication from the application tier.
- Application tier – business logic element, which has business-specific functionality and usually does most of the processing.
- Data tier – responsible for data processing and storage.
Let’s imagine a banking system again. Most banks deal with petabytes of data. In such an environment, data-related processes run on a dedicated server and are managed by a dedicated software – a database software. In the earlier examples, we assumed that the server already had some database “inside”. But in this case, the database is going to be placed somewhere else, e.g. on another server. So the application tier – a business logic server, while processing the request, will send a request to get or store some data to the data tier – the database server. And again, these two servers can be in two different physical locations. What’s more, the user is not even aware that there are two servers underneath, they still interact with the banking system through a web browser or a banking application.
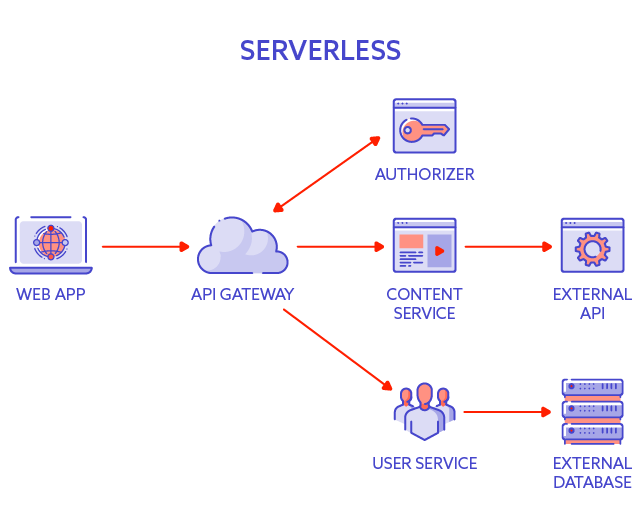
Serverless (cloud)
Is it possible to have a modern system without a server? A serverless architecture?
To some extent, yes – the cloud is the keyword!
But what is the cloud? For our purposes, we’re going to define cloud as computing power and storage capability that can be leased for a particular timespan and a particular purpose.
What is essential about the cloud is that both the user and the software owner do not need to know where the server/s is/are physically located. For example, when we analysed the banking system, you probably noticed that the user connects to the bank’s server and doesn’t need to know where that server is. However, the bank does need to know. With the cloud, the bank doesn’t need to know, either! It is somewhere in the cloud and the cloud provider needs to make sure the computing resources are available to the bank, but their physical location is secondary.
Modern clouds offer not only computing power and storage capabilities, but also other services, e.g. authorisation service or database service, to make the development and deployment of applications in the cloud easier and faster.
Flexibility and scalability with a cloud model
Cloud customers need to take care of the right level of computing power and storage capability, but it’s not fixed – it can change over time. In a client-server architecture, if a bank currently has 1 million customers and one server, it may find that when the number of customers grows to 2 million, it will be necessary to have additional servers to process all the requests.
Buying and deploying a new physical server might be quite a time-consuming process. However, scaling the resources up in the cloud is probably going to be way easier – simply order more computing power, and that’s it – it is at your disposal within a matter of minutes. The scaling process might require additional changes to your software, but it concerns serverless and client-server architectures. Even more exciting is that the bank can rent the computing power for a defined time, e.g. quarter of a year if they want to.
What if you only need a little computing power at night due to the fluctuating activity of your users in the twenty-four hours timeframe? With the cloud, you can only pay for what you use. The cloud gives you flexibility. That makes the cloud a great way to reduce costs and gain scalability on demand.
If you have tens of thousands of daily users but only a few hundred at night, you can manage your resources accordingly and what you end up paying for is just the computing power you are actually using. The resource you don’t consume overnight will transfer somewhere else and be consumed by someone who pays for it at the time. So it’s a win-win situation for a cloud customer and a cloud provider and leads to optimal utilisation of resources.
STABILITY
When you have one server that goes down for whatever reason, the whole system is down, and users can’t use it until the failure is eliminated. Using the cloud, you don’t have to worry about it. Every cloud provider has a unique mechanism developed to give you another server quickly, so your system can be unavailable only for a minute or two. That’s another reason so many companies decided to move to the cloud.
PAY FOR AS MUCH AS YOU NEED
Cloud rates are flexible. Large entities can negotiate individual rates to get even more cost-effective. It’s also worth remembering that you can set payment limits as a client. For example, you can determine that you will only pay a certain amount per month. Careful, though – once you’ve reached the limit, you’ve also exhausted the resources, so your system is not operational. In general, the cloud gives you better control over your costs.
PS. If you want to start or develop your career as a software engineer, we invite you to take a look at our career section. We are always keen to get in touch with promising candidates!
About the author
Kamil Szatkowski
Wroclaw Site Manager
Our blog



